
1 背景与核心痛点
- 行业现状
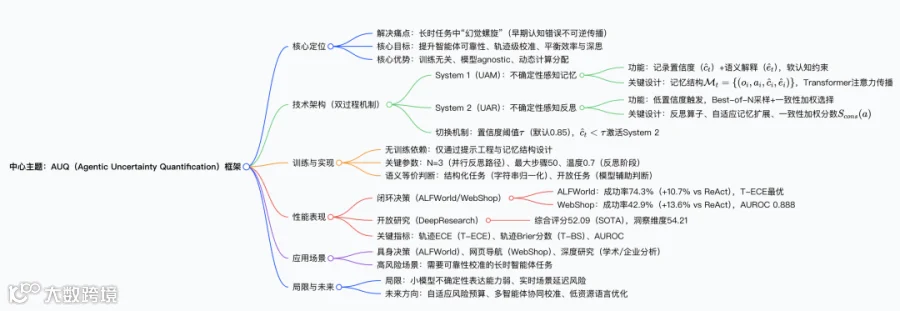
LLM 智能体在长时任务(如具身决策、深度研究)中表现出强推理能力,但面临 “幻觉螺旋”(Spiral of Hallucination)痛点 —— 早期认知错误(epistemic error)不可逆传播,导致任务失败。 - 现有方案不足
-
不确定性量化(UQ)方法:仅被动诊断风险,无法主动修正; -
自反思机制:盲目触发或无目标修正,导致计算低效或 “谄媚效应”(为错误辩护)。 - 核心目标
将不确定性转化为双向控制信号(正向约束传播 + 反向校准修正),实现 “感知 - 决策 - 修正” 闭环,提升智能体可靠性。
2 方法:双过程 AUQ 框架
2.1 核心设计理念
-
分解为两大数学问题: - 正向问题(不确定性传播)
估计轨迹有效性,防止错误固化; - 反向问题(不确定性校准)
通过推理时计算修正偏差,最大化任务成功概率。
2.2 双过程机制细节
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
.2.3 切换与执行流程
-
初始化:记忆,环境观测; -
System 1 执行:生成动作、置信度、解释; -
阈值判断:直接执行,否则激活 System 2; -
System 2 反思:生成修正动作,更新置信度与解释; -
记忆更新:。
3 实验:设计与核心结果
3.1 实验设置
- 数据集
3 类基准覆盖不同智能体场景: -
ALFWorld:具身决策(140 个环境,成功率指标); -
WebShop:网页导航(140 个 episode,成功率指标); -
DeepResearch Bench:开放深度研究(100 个 PhD 级任务,RACE 评分)。 - 基线对比
ReAct、Reflexion、Self-Reflection、CoT-SC。 - 模型支持
GPT-5.1、GPT-4.1、GPT-4o、Gemini-2.5-Pro、Qwen3-235B 等。
3.2 核心性能结果
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- 关键发现
-
双过程协同:UAM 提升校准(最低 T-ECE),UAR 提升锐度(最低 T-BS); -
开放任务优势:DeepResearch 中 “洞察” 维度达 54.21(SOTA),避免表面化总结; -
模型泛化:跨 8 种 LLM 均有提升,平均相对改进 + 6.4%。
4 关键分析
4.1 内部信念动态
-
置信度演化:UAM 轨迹置信度持续较低,抑制盲目决策;AUQ 轨迹在反思后显著反弹,消除不确定性; -
修正效率:修正 14.3% 的 ReAct 失败案例,仅 3.6% 的成功案例退化(4:1 净修复比)。
4.2 成本效率
-
帕累托最优:时平衡成功率与计算成本,API 调用量未指数增长; -
动态计算分配:System 2 仅在高风险步骤投入计算,避免 ReAct 的无效循环(失败轨迹平均 50 步→AUQ 修正后 18.1 步)。 -
5 局限与伦理 - 局限
小模型(<7B 参数)不确定性表达能力弱;实时场景存在延迟峰值;极端案例可能出现 “妄想确认”; - 伦理考量
需避免用户过度依赖置信度;通过 “自适应风险预算” 降低计算能耗。
关键问题Q&A
问题 1(核心创新层面):AUQ 框架的核心创新是什么?如何针对性解决 “幻觉螺旋” 问题?
答案:AUQ 的核心创新是将不确定性从被动诊断信号转化为主动双向控制信号的双过程架构,这是首个从 “正向传播 + 反向校准” 双维度解决幻觉螺旋的框架。具体解决方案:① 正向层面(System 1/UAM):通过记忆保留语言化置信度与解释,利用 Transformer 注意力形成软约束,抑制早期错误固化为 “伪事实”;② 反向层面(System 2/UAR):以解释为精准线索,仅在置信度低于阈值时触发目标性反思,通过并行路径采样与一致性加权,修正认知缺口而非盲目重试;③ 训练无关设计:无需微调,通过提示工程与记忆结构实现,适配各类 LLM,解决现有方案 “诊断与修正脱节” 的痛点。
问题 2(技术机制层面):System 1 与 System 2 的具体功能边界、协同机制是什么?如何平衡效率与可靠性?
答案:① 功能边界:System 1 是默认 “快速通道”,负责日常高效执行与不确定性传播,核心价值是 “防错”;System 2 是 “干预通道”,负责低置信度步骤的深度修正,核心价值是 “纠错”;② 协同机制:通过置信度阈值(默认 0.85)实现自适应切换 ——时 System 1 直接执行(低开销),时激活 System 2(针对性高开销);③ 平衡策略:1. 记忆效率:UAM 仅存储关键元数据(置信度 + 解释),避免上下文膨胀;2. 计算效率:System 2 采用 Best-of-N(N=3)而非更多采样,自适应记忆扩展仅在必要时加载完整历史;3. 决策效率:成功轨迹中 AUQ 更早识别目标完成(13.7 步 vs ReAct 16.2 步),失败轨迹中提前终止无效循环,整体降低 “无效计算” 成本。
问题 3(实际应用层面):AUQ 在不同场景中的性能优势如何?其成本效率对企业落地有何意义?
答案:① 性能优势:在三类核心场景中均实现 SOTA 级提升 —— 具身决策(ALFWorld 成功率 74.3%)、网页导航(WebShop 42.9%)、开放研究(DeepResearch 综合评分 52.09),尤其在长时、高风险任务中表现突出(如 DeepResearch 的 “洞察” 维度 54.21,远超闭源基线);② 成本效率意义:1. 降低失败成本:避免 ReAct 等基线在幻觉螺旋中消耗的大量无效计算(如 WebShop 失败轨迹从 50 步降至 18.1 步);2. 优化资源分配:动态将计算资源投向高风险步骤,而非全局反思(时帕累托最优,成功率提升而成本未指数增长);3. 降低落地门槛:训练无关设计适配企业现有 LLM 栈,无需额外标注或微调成本,同时支持多模型泛化(跨 8 种 LLM 均有效),大幅降低企业部署的技术与经济成本。