

本次发布的 Qwen3.5 是 QwenTeam 推出的原生多模态智能体,核心模型为 Qwen3.5-397B-A17B,整体在模型性能、预训练、基础设施、实际应用等方面实现全方位升级,以下为详细内容:
- 模型发布与核心特性
-
发布时间:2026 年 02 月 16 日,同步开放Qwen3.5-397B-A17B的开放权重版本,其 API 版本Qwen3.5-Plus通过阿里云百炼提供服务。 -
架构创新:采用 ** 线性注意力(Gated Delta Networks)+ 稀疏混合专家(MoE)** 的混合架构,兼顾能力与效率。 -
参数量:总参数量达3970 亿,每次前向传播仅激活170 亿参数,大幅优化推理速度与成本。 -
语言支持:将语言 / 方言支持从 119 种扩展至201 种,提升全球可用性;API 版本拥有1M token上下文窗口,支持官方工具及自适应调用。 -
- 模型表现:多模态基准评估对标前沿模型
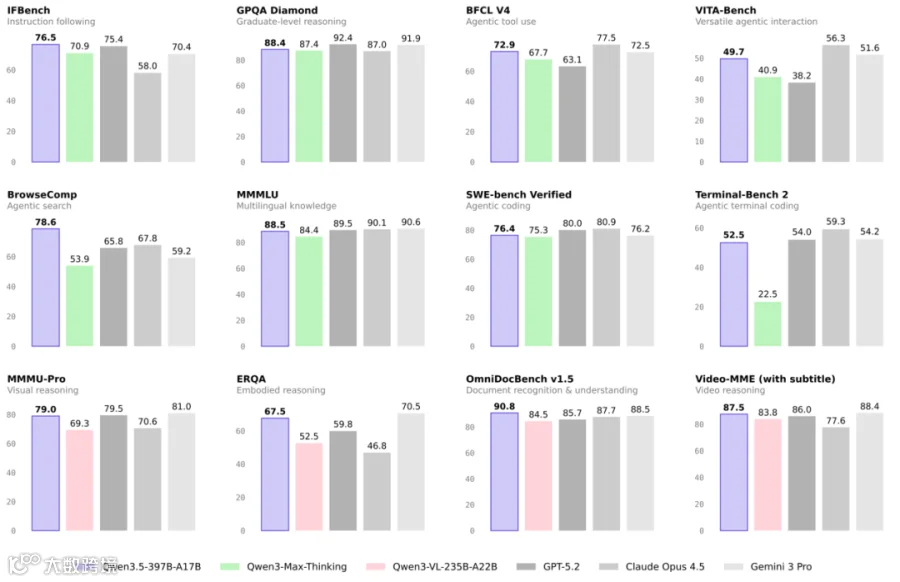
Qwen3.5-397B-A17B 在自然语言、视觉语言两大核心维度开展评估,对比 GPT5.2、Claude 4.5 Opus、Gemini-3 Pro 等前沿模型,多项指标表现优异,部分指标超越 Qwen3 系列原有模型,核心基准得分如下表: 评估维度 核心基准 Qwen3.5-397B-A17B 得分 关键对比优势 自然语言 IFBench(指令跟随) 76.5 高于 GPT5.2(75.4)、Claude 4.5 Opus(58.0) 自然语言 GPQA(研究生级推理) 88.4 高于 Claude 4.5 Opus(87.0)、Qwen3-Max-Thinking(87.4) 自然语言 MMMLU(多语言知识) 88.5 接近 Gemini-3 Pro(90.6),大幅优于 Qwen3-Max-Thinking(84.4) 视觉语言 OmniDocBench1.5(文档理解) 90.8 高于 GPT5.2(85.7)、Claude 4.5 Opus(87.7) 视觉语言 MathVision(STEM 解谜) 88.6 高于 GPT5.2(83.0)、Gemini-3 Pro(86.6) 视觉语言 Video-MME(带字幕,视频推理) 87.5 接近 GPT5.2(86.0)、Gemini-3 Pro(88.4) -
通用 Agent 能力:通过扩展 RL 训练环境,模型在 BFCL-V4、VITA-Bench 等 Agent 基准的平均排名显著提升,优于 Qwen3-Max-Thinking 等模型。 - 预训练:三大维度实现跨代升级
Qwen3.5 从能力、效率、通用性三个维度推进预训练,实现性能与效率的双重提升,核心优化成果如下: -
能力:在更大规模视觉 - 文本语料上训练,强化中英文、多语言、STEM 与推理数据并严格过滤,Qwen3.5-397B-A17B与参数量超 1T 的Qwen3-Max-Base表现相当。 -
效率:基于 Qwen3-Next 架构,融合更高稀疏度 MoE、混合注意力等技术,32k/256k 上下文长度下,解码吞吐量分别为 Qwen3-Max 的 8.6 倍 / 19.0 倍,为 Qwen3-235B-A22B 的 3.5 倍 / 7.2 倍。 -
通用性:实现早期文本 - 视觉融合的原生多模态,相近规模下优于 Qwen3-VL;词表扩充至25 万(原 15 万),多数语言编码 / 解码效率提升10–60%。 - 基础设施:高效训练与框架支撑
依托异构基础设施和定制化强化学习框架,实现 Qwen3.5 的高效训练与规模化扩展: -
异构训练架构:视觉与语言组件解耦并行,稀疏激活实现跨模块计算重叠,混合文本 - 图像 - 视频数据训练吞吐达近 100%。 -
原生 FP8 流水线:对激活、MoE 路由等采用低精度,敏感层保留 BF16,实现激活显存降低约 50%、训练加速超 10%,可稳定扩展至数万亿 token。 -
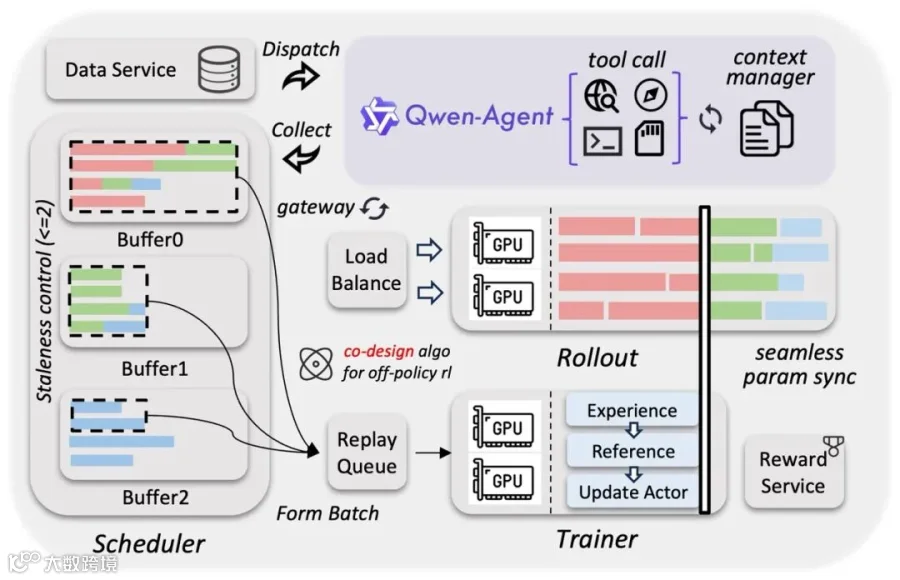
可扩展异步强化学习框架:训推分离设计,提升硬件利用率,支持动态负载均衡和细粒度故障恢复;结合 FP8 训推、投机采样等技术,端到端加速 3×–5×,可扩展百万级 Agent 脚手架与环境,增强模型泛化能力。 - 使用方式:多渠道交互与灵活调用
Qwen3.5 提供两种核心使用方式,支持个人用户与开发者 / 企业的不同需求: -
Qwen Chat 交互:提供自动、思考、快速三种模式,自动模式支持自适应思考 + 工具调用(搜索、代码解释器),思考模式针对难题深度推理,快速模式直接回答不消耗思考 token。 -
阿里云百炼 API 调用:支持调用旗舰模型 Qwen3.5-Plus,通过传入 enable_thinking(开启链式推理)、enable_search(开启联网搜索 + Code Interpreter)参数实现高级能力;可无缝集成 Qwen Code、OpenClaw 等第三方编程工具,实现流畅的 vibe coding 体验。 - 核心能力演示:多场景智能体落地
Qwen3.5 具备强大的代码智能体与视觉智能体能力,可落地于多个实际场景,核心能力包括: -
代码及智能体:支持网页开发、游戏代码生成,与 OpenClaw 集成实现搜索 + 报告生成,基于 Qwen Code 实现自然语言转代码、实时迭代开发的 vibe coding。 -
视觉智能体:可自主操作手机 / 电脑完成 GUI 任务(如 Excel 数据整理);视觉编程可将手绘草图转前端代码、游戏视频还原逻辑;空间智能具备精准的物体计数、位置判断能力,适用于自动驾驶场景理解;还支持带图推理(如迷宫最短路径求解)、视觉推理(如找不同、学科解题)等精细化视觉分析。 - 总结与未来工作
-
现有成果:Qwen3.5 凭借高效混合架构与原生多模态推理,为通用数字智能体奠定坚实基础,在推理、编程、多模态理解等方面显著提升生产力。 -
未来方向:从模型规模转向系统整合,重点构建具备跨会话持久记忆的智能体、面向真实世界的具身接口、自我改进机制,目标打造长期自主运行、逻辑一致的系统,将任务型助手升级为可持续、可信任的伙伴。 - 引用规范
若 Qwen3.5 对研究 / 开发有帮助,可通过指定 bibtex 格式引用,标注标题《Qwen3.5: Accelerating Productivity with Native Multimodal Agents》、博客地址、作者 Qwen Team 及发布时间 2026 年 2 月。 -
关键问题Q&A
问题 1(架构与效率):Qwen3.5-397B-A17B 的核心架构设计有何创新?该设计如何实现效率与能力的平衡?
答案:核心架构创新为采用线性注意力(Gated Delta Networks)与稀疏混合专家(MoE)相结合的混合架构;同时基于 Qwen3-Next 架构做了进一步优化,融合更高稀疏度的 MoE、Gated DeltaNet + Gated Attention 混合注意力、稳定性优化与多 token 预测技术。效率与能力的平衡体现在:一是参数量设计上,总参数量达 3970 亿保障模型能力,而每次前向传播仅激活 170 亿参数,大幅降低推理的计算成本与速度;二是解码吞吐量大幅提升,32k/256k 上下文长度下,其解码吞吐量分别是 Qwen3-Max 的 8.6 倍 / 19.0 倍,且性能与参数量超 1T 的 Qwen3-Max-Base 持平;三是依托异构基础设施的稀疏激活实现跨模块计算重叠,在混合模态数据上达到近 100% 的训练吞吐,兼顾训练效率与多模态能力。
问题 2(性能表现):Qwen3.5 在多模态能力上的核心优势体现在哪些方面?有哪些关键基准数据可以佐证?
答案:Qwen3.5 的原生多模态核心优势体现在STEM 解谜、文档识别与理解、视频推理、空间智能、视觉精细化推理五大方面,且相近规模下性能优于 Qwen3-VL,多项基准得分追平或超越 GPT5.2、Claude 4.5 Opus 等前沿模型。关键佐证数据:①文档理解方面,OmniDocBench1.5 得分 90.8,高于 GPT5.2(85.7)、Claude 4.5 Opus(87.7);②STEM 解谜方面,MathVision 得分 88.6,高于 GPT5.2(83.0)、Gemini-3 Pro(86.6);③视频推理方面,带字幕的 Video-MME 得分 87.5,接近 GPT5.2(86.0)与 Gemini-3 Pro(88.4);④空间智能方面,CountBench 得分 97.2,接近 Gemini-3 Pro(97.3),RefCOCO (avg) 得分 92.3,优于 Qwen3-VL-235B-A22B(91.1);⑤视觉推理方面,HallusionBench 得分 71.4,高于 GPT5.2(65.2)、Claude 4.5 Opus(64.1)。
问题 3(实际应用):开发者 / 企业如何调用 Qwen3.5 的高级能力?其支持哪些实际场景的落地应用?
答案:1. 高级能力调用方式:可通过阿里云百炼调用 Qwen3.5-Plus 的 API 版本,通过在请求中传入enable_thinking(开启链式推理的推理模式)、enable_search(开启联网搜索与 Code Interpreter)参数,即可启用推理、联网、代码解释等高级能力;同时该 API 可无缝集成 Qwen Code、Claude Code、OpenClaw 等第三方编程工具,实现更丰富的功能扩展。此外,普通用户可通过 Qwen Chat 的自动模式直接使用自适应思考与工具调用的高级能力。2. 落地应用场景:①代码开发场景:网页开发、游戏代码生成、实时迭代的 vibe coding、结构化报告生成;②办公自动化场景:自主操作 Excel / 电脑 / 手机完成数据整理、多步骤流程自动化;③视觉创作与分析场景:手绘草图转前端代码、游戏视频逻辑还原、长视频内容结构化提炼;④智能分析场景:自动驾驶场景理解、机器人导航、迷宫求解、找不同、学科解题等视觉推理与空间分析。