

编者摘要: 运行OpenClaw 3 周后出现MEMORY.md 膨胀至427 行、单次加载消耗2 万token、AI 因信息淹没响应变蠢的问题,还发现社区普遍存在上下文溢出、token 成本暴涨、手动维护繁琐等痛点,遂参考@ohxiyu 的优先级标签记忆管理方案,落地了热记忆、冷记忆、原始日志的三层记忆架构,编写memory-janitor.py自动归档脚本并将核心规则精简至5 条,过程中解决了正则匹配过宽、无原子写入等4 个技术坑,最终实现token 降低78%、记忆行数减少77%,AI 回答质量更精准;该方案仅实现了成本优化与维护自动化,靠读取文件让AI Agent “假装” 有记忆,并未解决真正的长期记忆问题,真正的长期记忆还需fine-tuning 或更强的RAG 技术支撑。
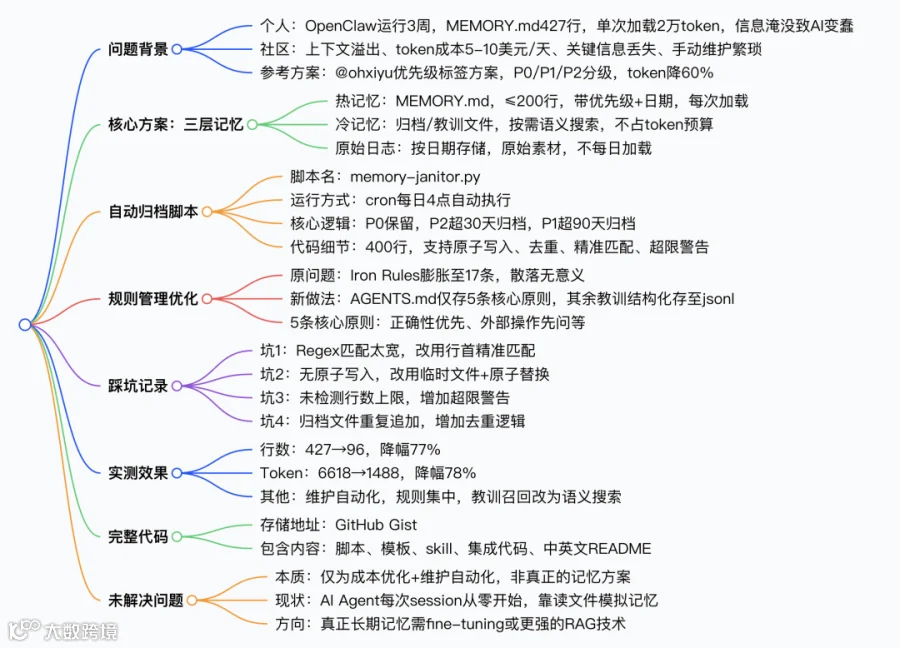
本文围绕OpenClaw 的AI Agent 记忆管理问题展开,从问题发现到方案落地、踩坑解决,最终实现了token 大幅降低和回答质量提升,同时明确了方案的局限性,具体内容如下:
1.问题发现:个人痛点+ 社区共性
o个人运行OpenClaw 3 周后,MEMORY.md 膨胀至427 行,每次对话启动需加载2 万token,因信息淹没导致AI “变蠢”,关键信息被忽略、无关信息反复提及。
o社区存在三大核心痛点:上下文溢出、token 成本高达5-10 美元/ 天且持续增长、手动维护记忆成本高,甚至出现关键信息(如API key)丢失的情况。
o参考@ohxiyu 的记忆管理方案,核心为给记忆加P0/P1/P2 优先级标签,该方案实现了**token 降低60%** 且回答质量提升,成为本次优化的基础。
2.核心落地:三层记忆架构设计
为解决信息冗余问题,设计了分层的记忆架构,各层分工明确、按需加载,每条热记忆必须附带优先级+ 日期,为自动归档提供基础:
o热记忆:存储于MEMORY.md,限制200 行以内,每次对话均加载,包含P0 核心身份、P1 活跃项目、P2 临时内容三类。
o冷记忆:过期内容迁移至memory/archive/,教训类内容结构化存储于memory/lessons/*.jsonl,按需通过memory_search 语义搜索召回,不占用每日token 预算。
o原始日志:按memory/YYYY-MM-DD.md 格式存储,保留原始记录素材,不参与每日加载。
3.自动化维护:memory-janitor.py 脚本开发
针对手动维护的弊端,编写了400 行的memory-janitor.py 自动归档脚本,通过cron 设置每日4 点自动运行,核心设计如下:
o核心逻辑:P0 优先级内容永久保留,P2 内容超过30 天归档,P1 内容超过90 天归档;
o边界处理:支持原子写入(先写临时文件再重命名,避免崩溃丢数据)、归档去重(防止重复归档)、行首精准匹配(避免误解析正文内的优先级标签)、超限警告(热记忆超200 行输出提醒)。
4.规则精简:核心原则仅保留5 条
o原问题:此前踩坑后无节制添加Iron Rule,最终膨胀至17 条且散落在文件中,无实际使用价值;
o新方案:AGENTS.md 仅存放5 条核心原则,其余踩坑记录均结构化存储至lessons/*.jsonl,需用时通过语义搜索“X 踩坑” 召回相关教训;
o5 条核心原则:真钱= 正确性> 速度、外部操作先问、自动化两套系统、长期进程用setsid 隔离、新平台先读结算规则。
5.问题解决:4 个核心技术坑及应对方案
方案落地过程中遇到4 个技术问题,均针对性优化解决:
o坑1:Regex 匹配太宽,用re.search () 误解析正文内的优先级标签,改为re.match ()+ 行首匹配精准识别bullet point 开头的记忆;
o坑2:无原子写入,直接覆盖文件易因崩溃导致文件损坏,改为先写.tmp 临时文件,再用os.replace () 原子替换;
o坑3:MAX_LINES 定义未生效,热记忆超200 行无提醒,添加超限检测逻辑,超行则输出warning;
o坑4:归档文件重复追加,同一天多次运行导致内容重复,改为读取已归档内容做去重后再写回。
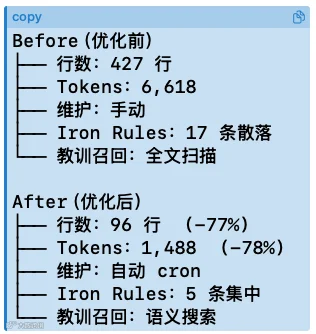
6.实测效果:token 降幅78%,回答质量提升
采用tiktoken 统计真实数据,优化前后的核心指标对比清晰,token 减少78%,且因信息噪音降低,AI 回答更精准,具体对比如下表:
对比维度
|
优化前
|
优化后
|
变化幅度
|
行数
|
427 行
|
96 行
|
-77%
|
Tokens
|
6618
|
1488
|
-78%
|
维护方式
|
手动
|
自动cron
|
自动化
|
Iron Rules
|
17 条(散落)
|
5 条(集中)
|
精简核心
|
教训召回
|
全文扫描
|
语义搜索
|
效率提升
|
注:token 计算为旧MEMORY.md 按15.5 tokens / 行测算,新MEMORY.md 直接统计为1488 tokens。
7.代码资源:完整可落地的工程化实现
所有代码均开源至GitHub Gist,包含scripts/memory-janitor.py、热记忆/ 教训/ 核心原则模板、OpenClaw skill、Claude Code 集成代码及中英文README,可直接落地使用。
8.方案局限:未解决真正的长期记忆问题
本次方案的本质是成本优化+ 维护自动化,并非让AI Agent 拥有真正的记忆:AI Agent 每次session 仍从零开始,仅靠读取文件“假装” 有记忆,P0/P1/P2 分级只是让该过程更高效;而实现真正的长期记忆,需要依赖fine-tuning(微调)或更强的RAG(检索增强生成)技术,这是后续的研究方向。
关键问题Q&A
问题1(方案设计侧):OpenClaw 记忆管理方案中,三层记忆架构的具体划分标准和使用方式是什么?
答案:三层记忆按使用频率、存储形式、token 消耗划分,热记忆为MEMORY.md 内≤200 行的带优先级+ 日期内容,每次对话均加载;冷记忆为过期归档内容和结构化教训文件,按需通过语义搜索召回,不占token 预算;原始日志为按日期命名的md 文件,仅保留原始素材,不参与每日加载。
问题2(落地效果侧):本次OpenClaw 记忆管理优化落地后,核心量化指标和使用体验分别有哪些提升?
答案:量化指标上,MEMORY.md 行数从427 行降至96 行,降幅77%,token 从6618 降至1488,降幅78%;使用体验上,实现了记忆维护的自动化(cron 每日自动归档),核心规则精简为5 条且集中管理,教训召回从低效的全文扫描改为高效的语义搜索,同时因信息噪音减少,AI Agent 的回答质量更精准。
问题3(方案局限侧):本次落地的OpenClaw 记忆管理方案并非真正的AI Agent 记忆方案,其核心局限性和未来的解决方向是什么?
答案:核心局限性为该方案仅实现了成本优化和维护自动化,AI Agent 每次session 仍从零开始,只是通过读取分层文件“假装” 有记忆,并未真正拥有长期记忆能力;未来的解决方向是实现AI Agent 的真正长期记忆,需要依托fine-tuning(模型微调)或者更强的RAG(检索增强生成)技术。
----------------------------------
AI Agent记忆越多反而越蠢?OpenClaw 记忆管理实战:三层架构+ 自动归档(Token 降78%)
Jason Zuo 2月11日
我的OpenClaw 跑了3周,
MEMORY.md膨胀到427 行。
每次对话启动,先吃掉2 万token 加载记忆。然后我发现一个荒谬的事实:记忆越多,AI 反而越蠢。
不是模型变差了,是信息淹没了。当你把400 多行记忆一股脑塞给LLM,它找不到关键信息,该记住的忘了,不该提的反复念叨。
1 问题有多严重?
翻了一下OpenClaw 的GitHub issues,发现我不是一个人:
#5771 — "2-3条消息后就overflow,即使删了所有memory"
#9142 — "$5-10/天的token 成本,context 一直增长"
#6622 — "API key在对话中收到,compaction 后就丢了"
社区最痛的问题:上下文溢出、成本暴涨、手动维护累死人。
然后我看到@ohxiyu
发的那篇记忆管理方案,核心思路是给记忆加优先级标签:
P0 —核心身份,永不过期
P1 —活跃项目,90 天过期
P2 —临时内容,30 天过期
他说token 降了60%,回答质量反而提升了。
我决定花点时间研究并落地这个方案。
2 最终方案:三层记忆
第一层:热记忆(每次加载)
MEMORY.md,限制在200 行以内。格式:

每条记忆带优先级+ 日期。没有这两个,自动归档就没法跑。
第二层:冷记忆(按需搜索)
过期的内容不删除,移到memory/archive/。
教训类内容存到memory/lessons/*.jsonl,结构化格式:

需要时用memory_search 语义搜索召回,不占每日token 预算。
第三层:原始日志
memory/YYYY-MM-DD.md保持不动,该怎么记怎么记。这是原始素材,不是每天加载的内容。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
3 自动归档脚本
手动维护必然失败。我写了个
memory-janitor.py,cron 每天4 点自动跑:
核心逻辑

完整代码400 行,处理了这些边界情况:
Atomic write —先写临时文件再rename,crash 不会丢数据
Dedup —同一天跑两次不会重复归档
行首匹配— 正文里的[P1] 不会被误解析
超限警告— 超过200 行输出warning
4 规则管理:只留5 条
我之前犯了个错:每次踩坑就往
MEMORY.md加一条Iron Rule。
结果Iron Rules 膨胀到17 条,散落在文件各处。记不住,也没用。
现在的做法:
AGENTS.md
只放5 条核心原则,其他教训存lessons/*.jsonl 用语义搜索召回。
我的5 条:
真钱= 正确性> 速度
外部操作先问
自动化两套系统(system crontab + OpenClaw cron)
长期进程用setsid 隔离
新平台先读结算规则
具体踩坑记录?搜索召回。做某事前跑一下memory_search("X 踩坑"),相关教训自动浮现。
5 踩坑记录
坑1:Regex 匹配太宽
第一版用
re.search
()找[P1][2026-02-10],结果正文里写"参考[P1] 的教训"也被解析了。
改成re.match() + 行首^\s*-\s*\[P,只匹配bullet point 开头。
坑2:没有atomic write
直接file.write_text() 覆盖原文件。如果写到一半crash,文件就废了。
改成先写.tmp 文件,再os.replace() 原子替换。
坑3:MAX_LINES 定义了没用
代码里写了MAX_LINES = 200,但从来没检查过。P0 膨胀到500 行也不会警告。
加了超限检测,超过200 行就输出warning 提醒手动清理。
坑4:归档文件用append
同一天跑两次,同样的内容归档两遍。
改成每次读取已归档内容做dedup,再写回。
6 效果:实测数据
用tiktoken 跑了一下真实da token 数:
具体计算:
新MEMORY.md
:96 行= 1,488 tokens
旧MEMORY.md
:427 行× 15.5 tokens/行≈ 6,618 tokens
减少:6,618 - 1,488 = 5,130 tokens
降幅:5,130 / 6,618 = 78%
Token降了78%,回答质量没下降,反而更精准了。噪音少了,信号就清晰了。
7 完整代码
GitHub Gist:
https://github.com/jzOcb/openclaw-memory-management
包含:
scripts/memory-janitor.py —自动归档脚本(atomic write、dedup、超限警告)
templates/MEMORY.md —热记忆模板
templates/lessons.jsonl —结构化教训格式
templates/AGENTS-rules.md — 5条核心原则示例
skills/memory-management/ — OpenClaw skill
claude-code/ — Claude Code集成
中英文README
8 这套方案没解决的问题
诚实说,这不是"让AI 有真正记忆"的方案。这是成本优化+ 维护自动化。
AI agent每次session 还是从零开始,靠读文件"假装"有记忆。P0/P1/P2 只是让这个假装更高效。
真正的长期记忆需要的是fine-tuning 或者更强的RAG。那是另一个话题了。
这篇讲了「怎么做」。
但你可能会问:搞这么复杂干嘛?128K context 不够塞吗?
我也这么想过。直到看到Anthropic 的解释👉Context Engineering:AI Agent 的真正核心
https://x.com/xxx111god/status/2021975762383876099
感谢@ohxiyu
的原始方案。我只是花一天把理论变成了可跑的代码。
有问题欢迎评论区讨论,或者直接在Github Gist下面提issue。