
上篇文章介绍了基于国产推理引擎赤兔在5090上部署Qwen-32B-FP4模型的教程,然而,我发现很多朋友还对FP4精度不是很熟悉,因此本文和下文在此背景下以精简的篇幅讲讲FP4数据类型以及用pytorch API写一个FP4 batch GEMV算子
本文主要专注于mxFP4/nvFP4数据类型的“最小化”知识
下文专注于基于pytorch API实现nvFP4 Batch GEMV算子和一些涉及到的blackwell架构知识
为了不让多数人看了第二天就忘了,我尽量避免知识的碎片化,不罗里吧嗦,做到每篇文章5分钟就看完并吸收。
在低精度推理领域,随着blackwell的发布,FP4精度正在被NV力推,其中FP4现今主要流行mxFP4和nvFP4两个版本,nvFP4看名字就知道是nv发布的,它是mxFP4方案的工程增强版。本文首先列举几点nvFP4的通用优势(注意,这并不是nvFP4相比mxFP4的优势,更不代表nvFP4在一切场景都优于mxFP4,我这里讲的是通用优势),然后对比两者核心差异,再深入解析nvFP4技术细节,给出nvFP4和mxFP4的选型建议,下文再用pytorch实现一个易懂的batch GEMV算子
nvFP4的核心优势
nvFP4的优势集中体现在效率、精度与兼容性三大核心维度,精准适配AI推理场景的核心需求:
- 性能显著提升:4位存储格式使显存占用量较FP32降低75%,GPU数据吞吐量提升数倍。以LLM任务为例,其推理速度可达FP16的2-3倍,大幅提升推理部署效率。
- 精度损失有效可控:通过优化量化策略减少数值误差,在ResNet、BERT等主流模型的推理任务中,精度损失相较于FP8不超过1%,实现了性能与精度的平衡。
- 软硬兼容性优异:深度适配NVIDIA Blackwell系列硬件及CUDA、TensorRT等软件栈,降低部署门槛。NV Blackwell第五代Tensor Core架构原生支持nvFP4,支持FP4数据的scale的动态缩放以及FP4 GEMM等核心运算。
nvFP4与mxFP4的核心差异解析
为明确nvFP4的技术优化价值,首先需对比其与mxFP4的核心差异:两者均为4位浮点数格式,数据结构一致,关键区别在于缩放策略——而缩放策略直接决定量化精度。nvFP4通过"细粒度+高精度"的双重优化,有效解决了mxFP4在某些精度敏感的场景下的精度瓶颈。
(零)nvFP4和mxFP4的共同点
二者都是一个block为量化粒度,为什么需要这么细的量化粒度?因为FP4表达范围有限,一共16个取值,后文会讲到。如果一个tensor都统一用一个scale,这个必定损失很多信息,所以为了精准表达数据原始信息,必须用一个block作为一个量化scale单位。相反,对于int8这种有256个取值的类型,那么多数模型(尤其是CV类)以tensor为量化scale单位,是可行的。
(一)mxFP4的技术局限
mxFP4采用1×32 block粒度的缩放策略,即32个元素共享1个缩放因子(scale),且scale类型为E8M0(对应的torch API为torch.float8_e8m0fnu),所以它的缺陷是仅支持2的幂次scale,粒度较粗且离散性强,易产生较大量化误差。
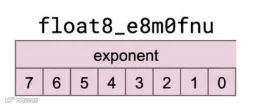
举例来说,若经校准算法(calibration)分析得出激活的最优scale为0.9,但由于E8M0仅能表示2^n(n为整数)形式的数值,可选择的近似值仅有2^-1=0.5和2^0=1.0。最终选取最接近0.9的1.0作为scale,由此产生的缩放误差约为(1.0-0.9)/0.9≈11.1%。
(二)nvFP4的针对性优化
针对mxFP4的精度瓶颈,nvFP4从三个维度进行优化,实现了精度与效率的平衡:
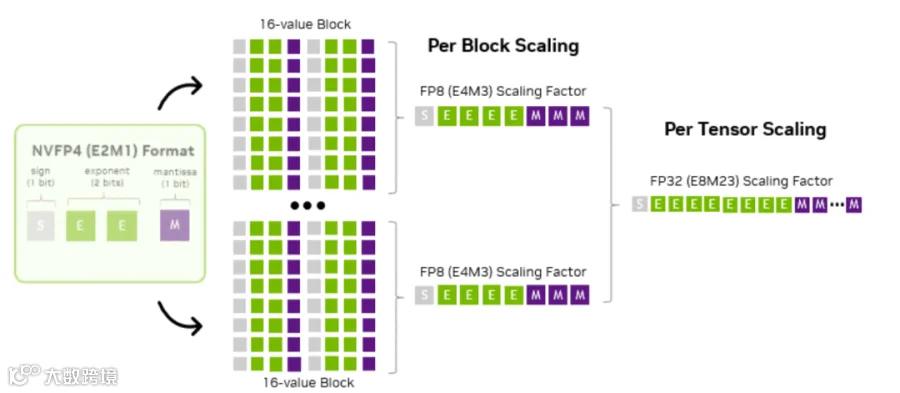
细粒度分块:采用1×16块粒度,即每16个元素独立配置1个scale,提升了scale对局部数据分布的鲁棒性,使量化误差降低30%以上。
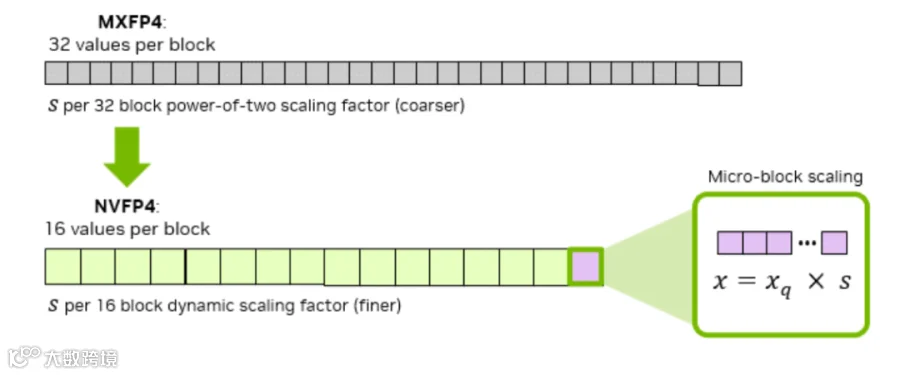
高精度scale:采用E4M3格式(对应torch.float8_e4m3fn),凭借3个尾数位的设计支持非2幂次缩放,数值表示能力显著提升。同样以最优scale为0.9为例,E4M3在[0.5,1.0]区间可表示0.5、0.5625、0.625、0.6875、0.75、0.8125、0.875、0.9375、1.0等多个数值,可选取最接近0.9的0.875作为scale,缩放误差仅为(0.875-0.9)/0.9≈-2.78%,远低于mxFP4。
全局误差补偿:引入1个FP32精度的全局scale,对E4M3局部scale进行微调,进一步降低整体量化误差。
所以,mxFP4和nvFP4之间没那么玄乎,区别仅此而已。
nvFP4的数据结构设计
nvFP4的核心数据结构在pytorch里面表示为torch.float4_e2m1fn_x2,通过"双元素打包存储"的设计,在保证精度的同时最大化存储效率——即把两个4位浮点数(float4)打包到1个字节(8bit)中存储。
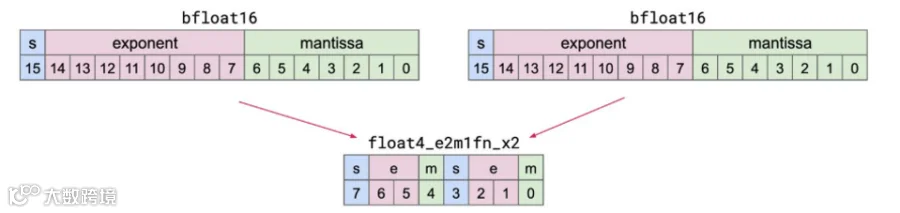
具体来看,单个float4采用"1位符号位+2位指数位+1位尾数位"(E2M1)的结构,其数值计算公式为:
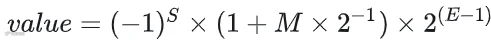
基于该结构,一个float4的数据共有16种可能取值,分别为[0, 0.5, 1, 1.5, 2, 3, 4, 6, -0, -0.5, -1, -1.5, -2, -3, -4, -6],可表示1.5、-2.0等非整数值,相较于INT4格式更适配神经网络参数的数值分布特性。
而"x2"标识的双元素打包存储设计,将2个4位数据分别存入1个字节的高4位和低4位,使存储效率翻倍。这一设计充分适配内存的字节级(8位)寻址特性:在未打包时,1个4位元素需占用1个字节,1024个float4元素共需1024字节;打包后,每2个4位元素占用1个字节,1024个元素仅需512字节,存储空间直接减半。同时,连续的存储方式更适配GPU的内存读取特性,进一步提升memory throughput。
nvFP4的量化实现方法
基于前述数据结构和缩放策略设计,nvFP4采用"高精度Scale+二级全局scale"的量化策略,流程简洁且精度可控:
(一)step1:小块(或者微块)级(blockwise)量化(精细缩放)
首先将完整tensor分割为多个小块,每个小块包含16个数;随后为每个小块独立计算1个E4M3格式的缩放因子,精准捕捉小块内部的局部动态范围。由于16个元素的数据分布相对均匀,E4M3格式的scale可实现高精度局部量化。
(二)step2:tensorwise量化(全局缩放)
经过小块级量化后,tensor已完成初步量化,但不同小块间可能存在整体偏差。为此,引入1个FP32精度的全局缩放因子,对所有小块的量化结果进行统一校准,进一步减小tensor层面的整体量化误差,确保量化后的数据分布与原始浮点数据分布的误差尽可能小。
基于上述二级缩放策略,原始浮点数x的量化公式为
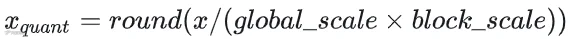
量化为nvFp4 ;示意图如下
反量化时则通过下式来恢复到原始精度
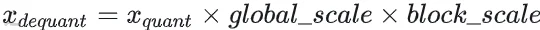
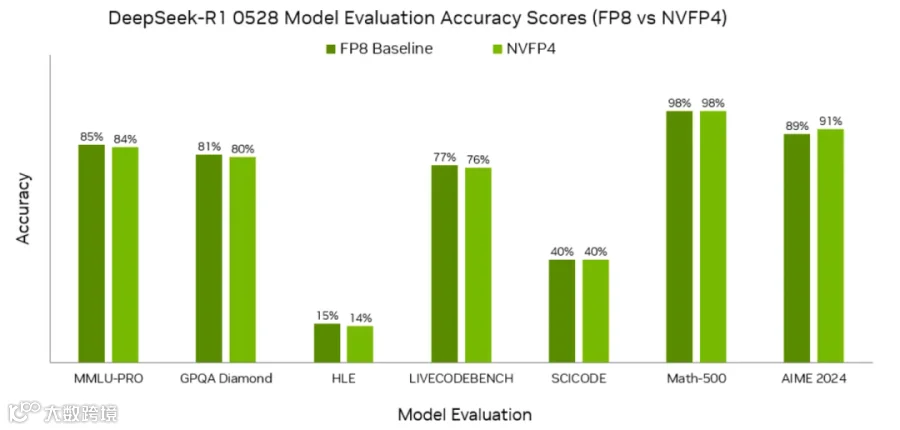
nvFP4的性能验证
低精度推理的核心目标是在提升性能的同时,最大限度维持模型的表达能力。nvFP4的设计精准实现了这一目标——以DeepSeek-R1-0528模型为例,在七项不同的评估任务中,nvFP4量化版本与FP8版本的精度差异极小,充分证明了nvFP4在极低精度下维持模型能力的出色表现。
选型建议
作为mxFP4的工程增强版本,nvFP4以"1×16细粒度分块+E4M3高精度缩放+全局误差补偿"为核心技术亮点,有效解决了经典4位量化方案的数值精度瓶颈,实现了性能与精度的更优平衡。
在实际选型中,根据场景需求灵活决策:若部署场景对简洁性要求较高,且处理的激活值、权重等数据对scale精度不敏感,mxFP4凭借更粗的分块粒度和无需全局校准的特性,可降低计算复杂度;若场景对量化精度要求较高,需在提升效率的同时严格控制精度损失,则nvFP4是更优选择。