
很多朋友一直在催课程5-2,上个月加班把视频录完了,这个月整理好了代码,今天终于发布!周末正好又有东西学了!
这是一个专门针对量化大模型的runtime(运行时),支撑课程5-1量化工具输出的量化模型在SM75/SM80/SM89(turing, ampere, ada卡)的高性能推理。课程5-1和5-2组成姊妹课程,完整呈现了量化这门技术的全过程:
1. 假设我手上有一个大语言模型Qwen3-8B,我想先把它量化压缩一下,且量化手段在AWQ/smoothquant/FP8里面选,那么使用课程5-1的量化工具分别采用这3个手段得到了4个不同的量化模型: Qwen3-8B-awq, Qwen3-8B-sq, Qwen3-8B-fp8-dyn (fp8动态量化), Qwen3-8B-fp8-static (fp8静态量化)
2. 得到了量化模型后,基于课程5-2,我想首先让量化后模型跑起来,然后测试一下它的文本生成表现或者精度,精度合格后,我还想测试一下它的性能数据,包括prefill阶段延迟和吞吐,decode阶段延迟和吞吐,同样地,以上数据,针对原始未量化的Qwen3-8B模型也来一套,再深入地,拿到两个模型的profile数据做做分析。二者作为对比,得到了全面的模型量化效果评估指标。Moreover,细讲涉及到的具体工作,我们想自己手搓低精度w4a16 gemm/gemv kernel,借助cutlass写一写FP8/int8 gemm kernel,并且小串讲一下cutlass 2.x,并且测一下它们和量化前朴素版本的性能提升对比,你以为这样就完了?当然没有,模型并不只是gemm,还有norm,attention等等,这些也得搓或者调。。至此,量化的故事已然全部道完,不管你的量化算法再花哨,你的推理引擎多难读懂,量化的底裤已被扒完。撒花~
课程5-2十大特点
以上巴拉巴拉了许多,基本上把课程5-2涵盖的内容讲得七七八八,接下来再罗列一下5-2的功能范围:
支持经5-1多个量化后大语言模型的运行,包括dense模型和moe模型,例如Qwen3,Qwen3-MoE,LLama3,LLama4-MoE,OPT等
支持多种量化模型的运行:awq、sq(smoothquant)、fp8
支持多种量化粒度gemm算子:伪代码先行,然后手写或者借助cutlass实现per tensor/per channel/per group/per token gemm,其中fp8 per token+per channel gemm使用cutlass EVT开发,一种非常好用的开发fusedGemm系列的功能
针对AWQ,在batch size<8的decode阶段额外支持gemv算子
严格的低精度gemm公式推导,面试高频
cutlass 2.x代码小串讲
hack transformers runtime以支持两种模式的量化模型运行时
非linear算子采用transformers风格开发,包含attention,滑动kv cache,norm等,浅显易懂
API与5-1保持高度相似,降低学习成本
完备的精度加性能测试脚本和数据,以证明课程5-1量化工具实现正确,课程5-2的量化runtime实现高效
前置知识
对transformer,大模型结构较熟悉
需熟悉python,最好略懂CUDA
建议与课程5-1配套食用
-
面试缺项目, 课程5-1和5-2单拎任何一个都可以作为简历上的一个项目,如果你不懂怎么写,那你到时可以找我
-
不熟悉大模型量化的anyone
课程目录
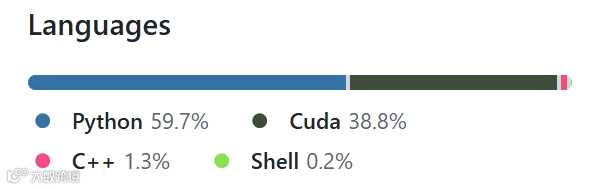
编程语言
课程发送内容
课件、代码和视频,以及课后答疑等等,具体可以加我我发一段完整的注意事项
购买方式
公众号主页菜单栏点击个人微信-->个人微信 加我即可。
价格
针对之前买过我的课的朋友: 809