为什么要量化 All-Reduce?
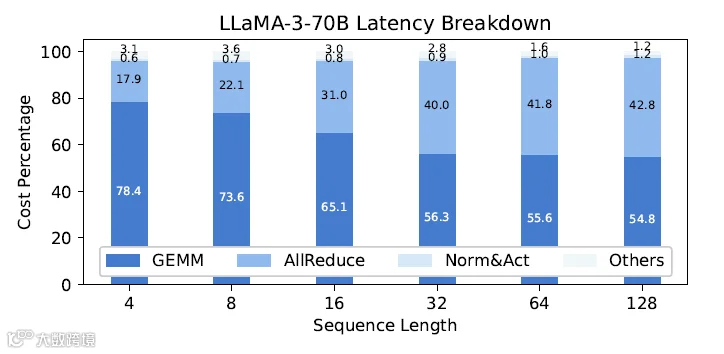
通信占推理延迟大头:LLaMA-3-70B 在 4×L40 上 All-Reduce 占 17 %-42.8%,数据来源论文,但是用的什么推理引擎测的,作者并没有介绍,这里是一个不严谨的地方。
低带宽 GPU 对通信延迟更加敏感:对于L40这种不支持nvlink的GPU,只能走PCIe总线,带宽为 64 GB/s ,通信替代计算成为了主要的瓶颈。
量化后的收益:受限于Quantize-Dequantize开销影响,低精度的nccl ring allreduce收益不是最优,具有可优化的地方
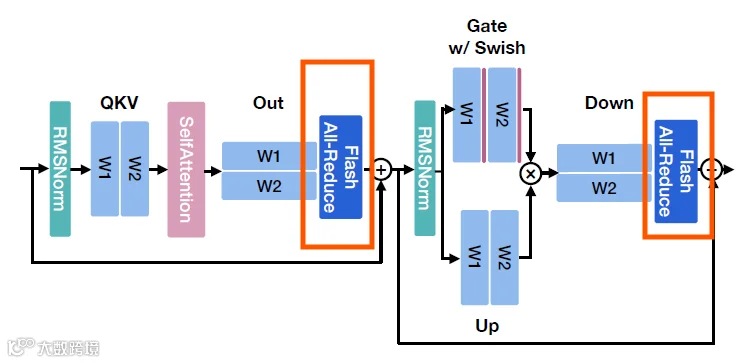
量化后的all reduce所在的位置在MLP block中的位置如下
通信压缩相关工作
在现有通信压缩方案里,各家瞄准的对象和场景并不相同:ZeRO++ 和 QSDP 只把权重或梯度压到 INT8/INT4,且仅用于训练阶段;EQuARX 率先在 TPU 推理中对激活值做 INT8 压缩,取得了显著的带宽收益;而 本文引用的论文则在 GPU 推理场景下推出 INT6 混合精度策略,专门针对激活值进行精度 All-Reduce,从而在多卡推理中实现更大的通信加速。这个是差异化的体现。
NCCL Ring All-Reduce 的低精度缺陷
对ring allreduce不熟悉的读者可以先读一下这篇文章https://zhuanlan.zhihu.com/p/469942194,本文略过ring allreduce的过程讲解
在传统 Ring 方案里,all reduce里面无论是 Reduce-Scatter 还是 All-Gather,每一个ring hop都要先对收到的低精度数据进行反量化,累加或拼接后再重新量化并跳转;这样两轮下来共产生 2(N−1) 次量化/反量化,Reduce scatter占N-1,all gather也占N-1,延迟随卡数N线性增长。同时,这些反复的 Q/DQ 计算在流水线中形成大量“计算气泡”,导致通信链路部分时间处于等待状态,通信带宽利用率下降,延迟上升,这也正是低精度 Ring All-Reduce 的致命缺陷。
OK,至此,有了以上对问题的分析之后,工作才有了意义。
低精度All-Reduce kernel的设计
算法非常简单:两步 custom All-Reduce取代ring All-Reduce。
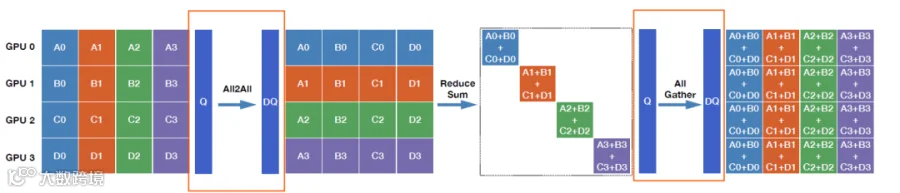
将All-Reduce拆解为Reduce scatter和all gather,前者进一步拆解为all2all和local reduce,这个拆解上一篇文章已经详细描述过。
如图所示:
All2All: 量化 1 次为低精度int4之后,分发到各GPU,通信数据类型为低精度int4
本地 Reduce:每个GPU上有部分行的全部数据,本地reduce即可,这里先反量化1次为高精度FP16/BF16做累加,然后再量化1次为低精度int8,准备做all gather,减少通信量
All-Gather:all gather收到后,反量化 1 次为高精度FP16/BF16
优化点:
1.总 Q/DQ 次数减小为 2 ,远小于Ring AllReduce 的 2(N-1)。通信数量保持不变,仍为 2M(N-1)/N(具体推导见https://zhuanlan.zhihu.com/p/469942194或其它网上文章,搜索all reduce通信量即可),但是类型呢量化为了int8/int4,通信大小降低了2~4倍。
2.避开了ring allreduce,采用Peer to peer的all2all和all gather即可减少QDQ次数
3.all2all 本地reduce allgather仍然被fuse为一个kernel,并不会带来额外启动开销,但是本文引用的论文并没有公开源码,具体实现不得而知
4.大家也注意到了,all2all的量化精度为int4,allgather的量化精度为int8,这个是为啥呢,因为前者只有round和clip误差,但是后者不仅有round和clip,还有本地reduce带来的accum误差,所以为了保险起见,后者用了int8精度
消融实验
定量实验部分,我准备省略,反正就是说它的这个方案在精度和速度上取得了更好的balance,速度比ring allreduce int8/int4都更好,源于QDQ数量的减少,精度呢,比pure int8差点,但是比pure int4好点,所以就是balance咯
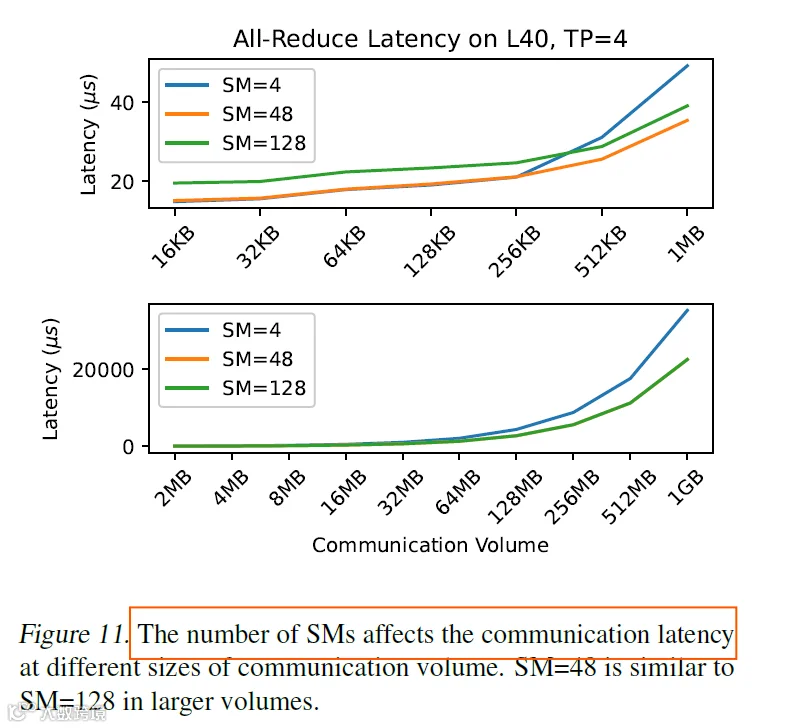
消融实验部分,个人觉得不咋地,尤其是论文5.3节部分,我心想,你源码反正没放出来,反正这个SM数量对于性能的影响取决于你代码的实现,你怎么说都对,个人觉得,这是不具有说服力的一组实验