
年初,清华大学与国内AI Infra企业清程极智联合开源了推理引擎—— 赤兔,其聚焦多元算力适配与高效算子优化的技术路线,展现出较强的成长性,受到行业关注。
随着大模型参数量持续提升,显存占用过高仍是私有化部署的核心痛点。NVIDIA Blackwell 架构的推出带来了关键硬件突破 —— 新增 FP4 浮点数计算单元,为 FP4 精度模型的高效运行提供了关键硬件支撑。依托于过往算子优化中积累的技术经验,赤兔团队敏锐捕捉这一硬件趋势,针对性完成了 FP4 算子的原生支持,可直接对接 Blackwell 的硬件计算能力。
目前赤兔已完成对 Qwen3 全系列模型的 FP4 量化适配,无论 Dense 还是 MoE 结构,都提供了完整的 FP4 量化方案与量化后模型。
接下来,我们聚焦实操环节:基于 NVIDIA Blackwell 架构的原生 FP4 计算单元特性,通过赤兔完成 Qwen3-32B FP4 精度模型的部署、配置调优和性能测试,全程步骤简洁可复现。
一、环境准备:硬件与软件配置
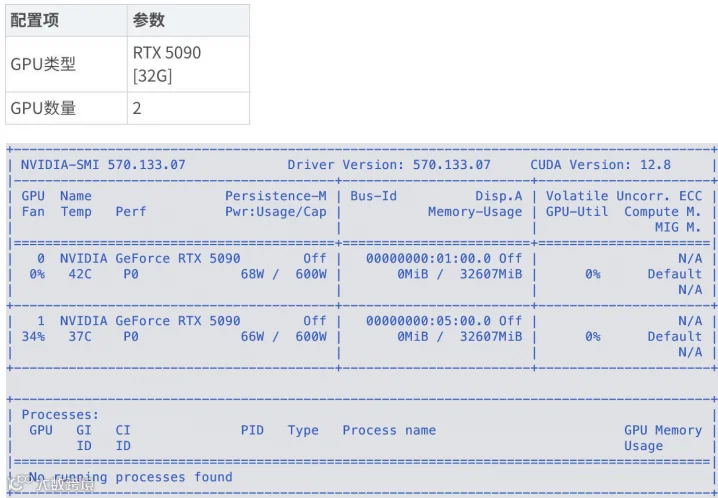
1. 我们使用的硬件配置如下
2. 软件上我们使用赤兔基于blackwell架构的最新镜像,如下
qingcheng-ai-cn-beijing.cr.volces.com/public/chitu-blackwell:v0.4.3

3. 模型我们从modelscope社区下载,https://www.modelscope.cn/models/qingcheng-ai/Qwen3-32B-fp4
pip install modelscopeexport MODELSCOPE_CACHE=非系统盘(/)localPathmodelscope download --model qingcheng-ai/Qwen3-32B-fp4
二、搭建赤兔推理环境
1.启动容器
第一步我们先启动镜像,注意需要将模型目录挂载到镜像中,如作者环境中,将模型提前下载到了 /data 目录
docker run --rm --gpus=all -it --privileged --shm-size=1g -v /data:/data -v /home/share/models:/home/share/models -v /usr/local/bin/grun:/usr/local/bin/grun:ro -v /tmp/gpu_locks:/tmp/gpu_locks qingcheng-ai-cn-beijing.cr.volces.com/public/chitu-blackwell:v0.4.3 bash
2.检查环境
我们主要检查镜像内赤兔和Pytorch的版本,注意对应 torch 的cuda 版本不要与宿主机差异过大。
pip list | grep chitupython -c "import torch; print(torch.__version__)"
3.启动赤兔
torchrun --nnodes 1 --nproc-per-node 2 \--master_port=22525 \-m chitu \serve.port=8001 \infer.cache_type=paged \models=Qwen3-32B-fp4 \models.ckpt_dir=/data/Qwen3-32B-fp4 \models.tokenizer_path=/data/Qwen3-32B-fp4 \infer.tp_size=2 \infer.pp_size=1 \infer.max_reqs=4 \request.max_new_tokens=4096 \dtype=bfloat16 \infer.attn_type=flash_attn \infer.use_cuda_graph=True \infer.raise_lower_bit_float_to=bfloat16
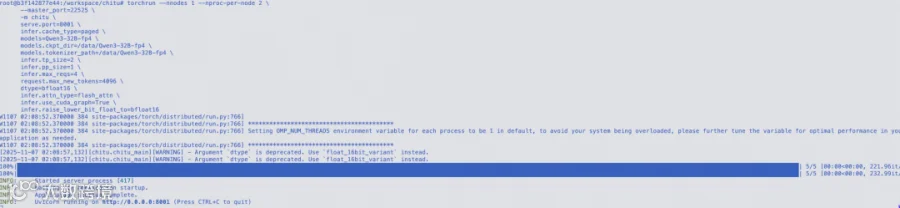
服务正常启动后输出以下结果,表示服务已经正常启动,并成功占用端口
三、服务验证
1. curl 调用
curl -X POST "http://0.0.0.0:8001/v1/chat/completions" \-H "Content-Type: application/json" \-d '{"model": "Qwen3-32B-fp4","messages": [{"role": "user","content": "你好"}],"max_tokens": 2048}'
预期得到正常的返回

且服务端会有接收到请求的日志打印

2. 性能测试,脚本见
https://github.com/thu-pacman/chitu/blob/public-main/benchmarks/benchmark_serving.py根据实际需求调整输入和输出长度(--input-len/--output-len)命令如下:
cd /workspace/chitu/benchmarks
MODEL=Qwen3-32B-fp4
BASE_URL=http://0.0.0.0:8001
OUTPUT_DIR=/root
for i in 1 2 4 8 16 32 64
do
python benchmark_serving.py \
--model ${MODEL}\
--batch-size ${i} \
--input-len 2048 \
--output-len 2048 \
--warmup 1 \
--iterations 1 \
--base-url ${BASE_URL} \
--output-dir ${OUTPUT_DIR} \
--append-result
done
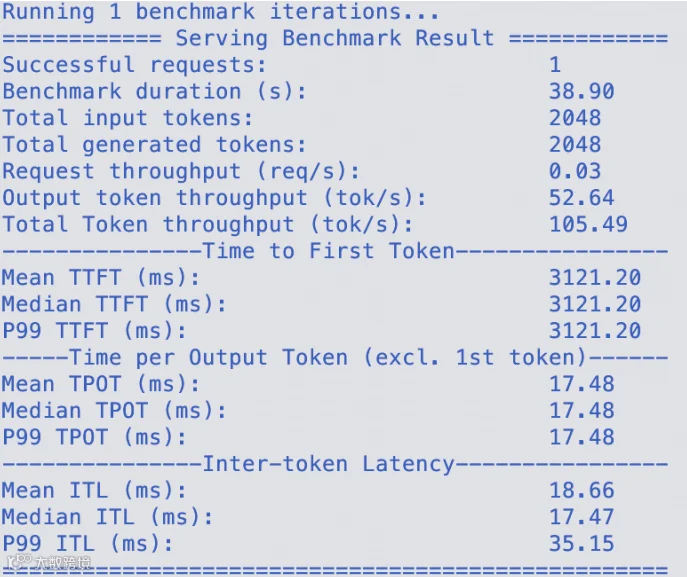
得到以下输出
赤兔开源地址,感兴趣的同学可以一试
https://github.com/thu-pacman/chitu
他们有个交流区:
