
上文卖了个关子,介绍了mxFP4/nvFP4的前置知识,本文开始进入正题,用pytorch写一个nvFP4 batched GEMV算子,纵然是pytorch,在搭建算子的时候也有很多涉及到要与blackwell架构协同的地方
NVFP4 Batched GEMV 概念阐述
gemv矩阵向量乘大家应该都知道怎么个算法,本文举例为左边A矩阵,右边x向量,二者做矩阵向量乘法得到一个向量y
对于通用FP4类型来讲,它不像mxFP4和nvFP4有block wise级别的scale,而是只有一个全局的tensor wise级别的scale,那么它的batch gemv公式如下
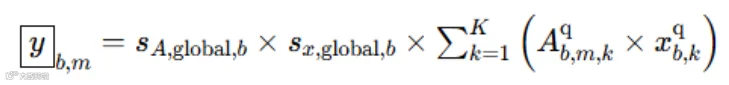
公式可解释为,先执行 FP4×FP4 逐元素乘法,在 reduce 维度 K 上累加后,通过全局缩放因子反量化,输出 FP32 结果,这其实也是所有低精度GEMM/GEMV非常典型的公式。
对于nvFP4类型来讲,上文也讲到核心是 16 个元素为一个小块,共享 FP8 缩放因子,最后全局共享一个fp32类型的缩放因子,因此它的batch gemv公式如下,注:⌊k/16⌋为reduce维度上第k个元素所属的小块id
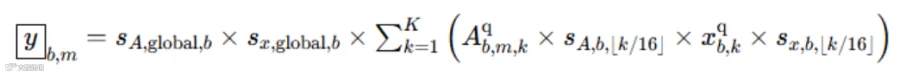
用cutlass的视角来看该gemv/gemm的话,blackwell第5代tensor core将不仅仅在mainloop计算A*x,而且会同时乘公式中的scale,省去了epilogue,这是在pre-blackwell架构上看不到的
以上公式的符号解析见文末附录,此处省去
NVFP4 Batched GEMV 实战代码
接下来,我们在以上公式的基础上,开始写代码
准备数据
# GEMV N dimension is always 1n = 1# Scaling factor needs to pad the N size to 128n_padded_128 = 128# Scaling factor needs to pad the N size to 128n_padded_128 = 128# Generate uint8 tensor, then convert to float4e2m1fn_x2 data typea_ref = torch.randint(0, 4, (l, m, k // 2), dtype=torch.uint8, device="cuda").permute(1, 2, 0)# Pad b tensor's N dimension to 128 to call torch._scaled_mm for nvfp4 dot product computationb_ref = torch.randint(0, 4, (l, n_padded_128, k // 2), dtype=torch.uint8, device="cuda").permute(1, 2, 0)a_ref = a_ref.view(torch.float4_e2m1fn_x2)b_ref = b_ref.view(torch.float4_e2m1fn_x2)# Create float16 output tensorc_ref = torch.randn((l, m, n), dtype=torch.float16, device="cuda").permute(1, 2, 0)
以上准备了输入矩阵A,输入向量B和输出向量C,有三点需要注意:
-
scale factor的维度我们pad到128,这个是blackwell tensor memory要求的 -
生成的a和b,都是按照uint8类型,并且k维度相应的除了2,这是因为我们在后面view成了 torch.float4_e2m1fn_x2,这与上文说的2个float4 pack为8bit相符 -
gemv的结果c的类型为高精度类型fp16
# nvFP4以1x16为一个blocksf_vec_size = 16# block的数量sf_k = k // sf_vec_sizemn = m # 对于a矩阵# mn = n_padded_128 # 对于b向量# Create the reference scale factor tensor (mn, sf_k, l) on CPU.ref_shape = (l, mn, sf_k)ref_permute_order = (1, 2, 0)# Init with uint8 tensor, then convert to float8_e4m3fnref_f8_random_int = torch.randint(0, 3, ref_shape, dtype=torch.int8, device='cuda')ref_f8_torch_tensor = ref_f8_random_int.to(dtype=torch.float8_e4m3fn)# permute to match ref_permute_ordersfa_ref = ref_f8_torch_tensor.permute(*ref_permute_order).to("cuda") # scale factor Asfb_ref = ref_f8_torch_tensor.permute(*ref_permute_order).to("cuda") # scale factor B
我们计划调用pytorch原生API torch._scaled_mm来做fp4 gemv/gemm,为了达到这个目的,以上准备了输入矩阵A和输入向量B的blockwise scale,类型为fp8,shape为[mn, sf_k, l]即每1x16看作1个block后的形状,思路比较简单,注意这是简化后的代码,无法直接运行
至此,gemv所需的全部数据(A, B, scale_factor_A, scale_factor_B)已经准备好,那我们就可以开始计算了,如下
pytorch实现NVFP4 batch gemv
def ref_kernel(a_ref, b_ref, sfa_ref, sfb_ref,c_ref):"""PyTorch implementation of NVFP4 block-scaled GEMV."""a_ref, b_ref, sfa_ref, sfb_ref, _, _, c_ref = data# Get dimensions from MxNxL layout_, _, l = c_ref.shape# Call torch._scaled_mm to compute the GEMV resultfor l_idx in range(l):# Convert the scale factor tensor to blocked formatscale_a = to_blocked(sfa_ref[:, :, l_idx])scale_b = to_blocked(sfb_ref[:, :, l_idx])# (m, k) @ (n, k).T -> (m, n)res = torch._scaled_mm(a_ref[:, :, l_idx],b_ref[:, :, l_idx].transpose(0, 1),scale_a,scale_b,bias=None,out_dtype=torch.float16,)c_ref[:, 0, l_idx] = res[:, 0]return c_ref
从代码看,主要流程还是很好理解,有一点略显晦涩,to_blocked这个函数一眼看上去不知道干嘛的,要搞清楚这个需要先弄清楚以下两个问题
关键的to_blocked函数理解
- torch._scaled_mm API完成fp4 blockwise gemm底层是如何实现的?
答:经过我的调查,调用的cuBLAS,参考Updated Scaled_mm to support more scaling formats via CuBlas · Issue #153555 · pytorch/pytorch (公众号无法插入外部链接,forgive me)
2. 在1的基础上,那么cublas对fp4 blockwise gemm的scale布局有什么要求?
答:见下图,参考自cuBLAS 13.0 documentation的3.1.4.3.2小节 (公众号无法插入外部链接,forgive me)
下图表示了cublas API针对fp4 gemm所接收的scale factor的layout要求:
首先scale数据必须在tensor memory,然后在该memory中的排布顺序见我的箭头标识,to_block里面的permute、transpose等操作就是把scale的内存布局变换成下图这样,以放进blackwell GPU里面的新玩意tensor memory(因为这玩意的行数为128,blackwell tensorcore要求AB矩阵的scale factor都必须放在这里面是为了避免scale占用寄存器,从而减小寄存器压力),进一步做mma(FP4精度下,MMA_M为128或256)
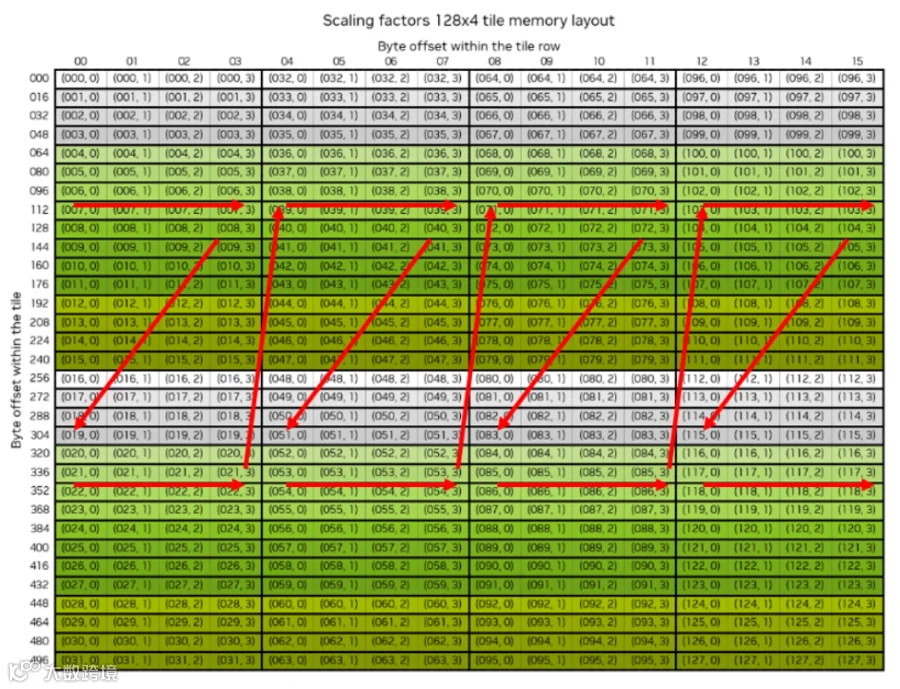
scale tile/scale_vec_size参数的理解
看到这里可能会好奇,为啥图上标题写着这是一个128x4的scale tile,并且代码上也是要求scale的行必须是128的倍数,列必须是4的倍数。128在之前解释过了,这里解释4。首先需要明确一些概念,blackwell里面"MMA"指令在ptx中表现为"tcgen05.mma",它支持很多类型的GEMM,如下
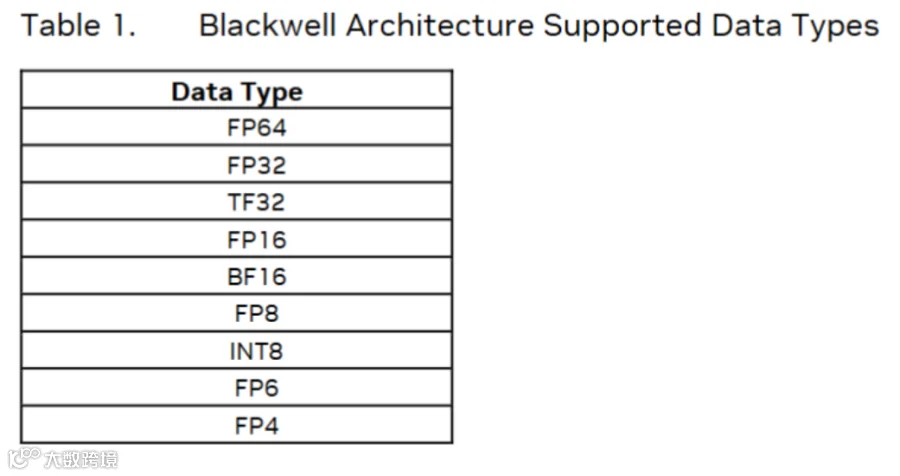
对于fp8 fp6 fp4数据类型,tensorcore原生支持scaled MAC,即下面公式的sAb和sxb的与A和x的MAC可以一起在tensorcore完成,这在pre-blackwell中是不支持的,scale的计算只能在cuda core完成
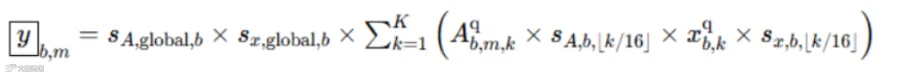
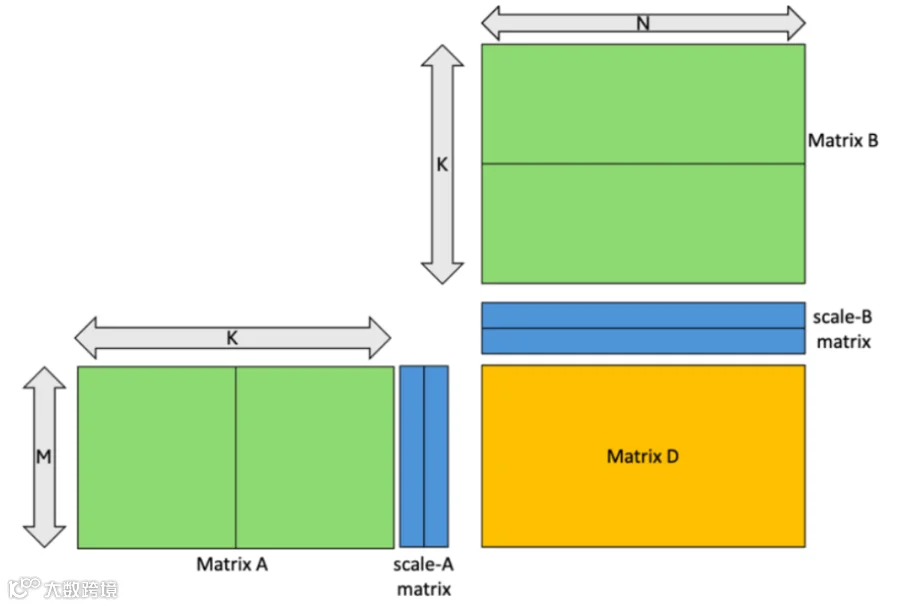
另外还有个概念是scale_vec_size,以下图为例,由于nvfp4要求1x16为一个块,所以A的一行32个元素被切成了两块,每块都有一个scale,对应scale-A matrix的一行一个元素
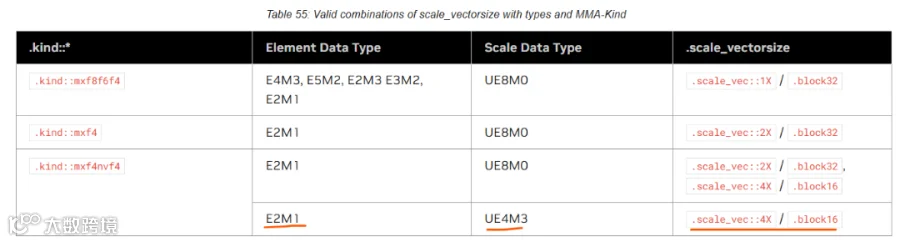
这个scale_vec_size呢,又有一些限制,如下nvfp4要求scale_vec_size为4,所以这也是128x4 scale tile中的4的来历
看到这里,基本解释清楚了to_blocked函数,如果你已经看累了,那可以忽略以下部分。
以下是一些关于blackwell架构的进一步理解
blackwell架构的进一步理解
1.关于 tensor memory,主要摘录于ptx文档和公开的gtc ppt。可以看到我标粗的部分,tensor memory的形状是[128, 512],每列的每个slot为4B,所以如果scale_vec_size为4的话,加上scale的类型为fp8,大小为1B,那么tensor memory可以最大化地被blackwell mma利用
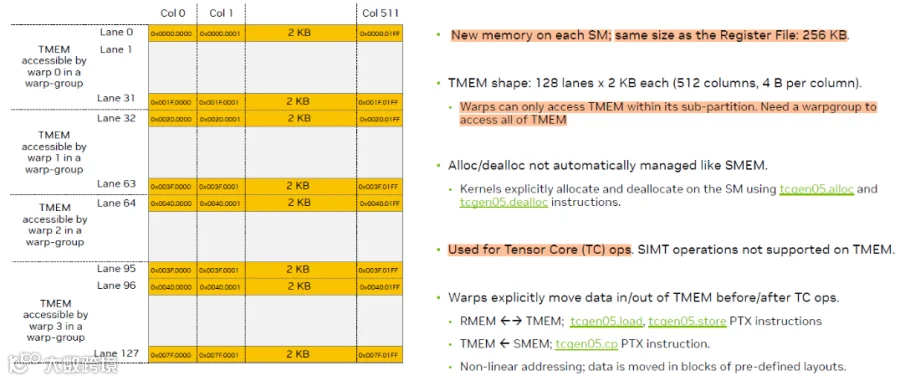
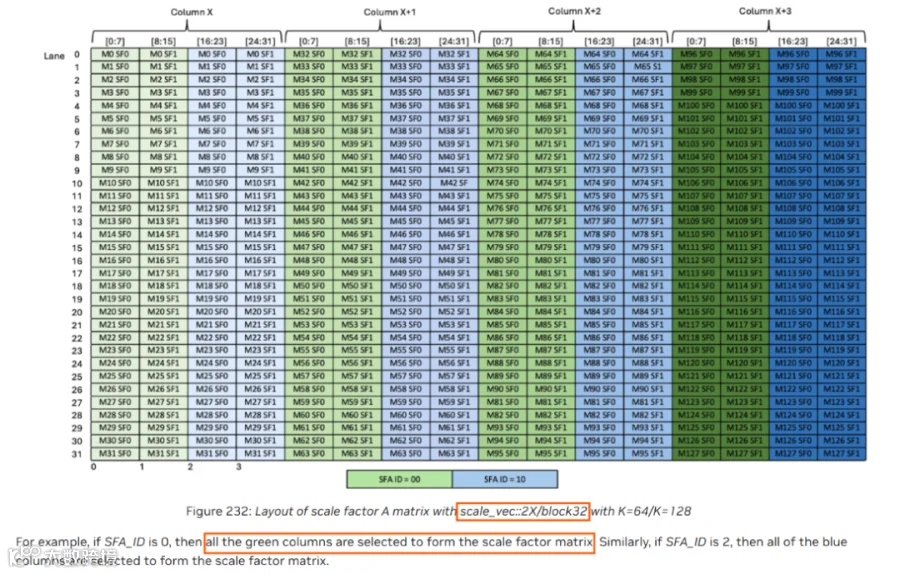
由此,也诞生了ptx文档中1. Introduction — PTX ISA 9.0 documentation这一部分的一长串对tensor memory中scale数据的访问解释,比如以下对blocksize=32,scale_vec_size=2时scale factor读取的描述
2.头先提到scale是放在tensor memory中,值得注意的是gemm的累加结果acc也是放在这个tensor memory里面,如下图
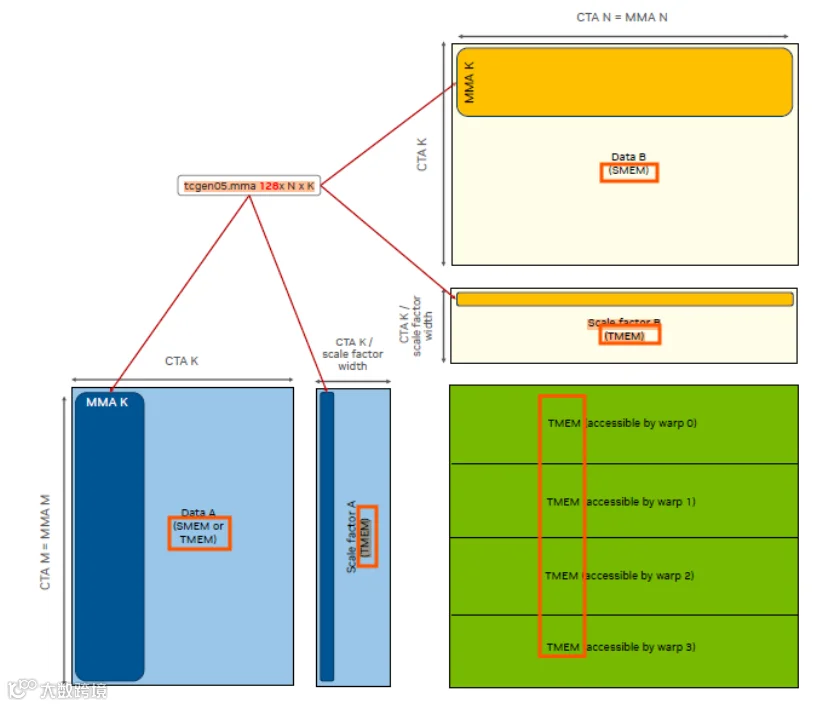
acc放在tensor memory的好处是什么呢?答:epilogue还是从寄存器中读数据来做store或者elementwise操作等等,这样epilogue不再强依赖于acc,而是可以达到mainloop和epilogue的完全异步,无需像hopper那样搞个pingpong schedule,这是在hopper基础上的一个演进
附录:

最后
随着N卡逐渐DSA化,甚至sm100还不兼容sm90的指令,手搓一个兼容的gemm/gemv已经变的不太现实或者不太优雅,cutlass/cute几乎成了开发sm90 gemm/sm10x gemm的唯一或最佳答案。