
原文地址 https://stats.idre.ucla.edu/r/dae/logit-regression/ Logit Regression | R data analysis Example
Logistic regression, also called a logit model, is used to model dichotomous outcome variables. In the logit model the log odds of the outcome is modeled as a linear combination of the predictor variables.(简单理解,逻辑斯蒂回归用于二分类结果建模)生词:dichotomous 对立的;二岐的 the log odds of the outcome
数据
探索GRE、GPA、Rank与研究生录取与否的关系,相应变量为二进制数据 GRE: Graduate Record Exam scores GPA: grade point average Rank: prestige of the undergradute institution A researcher is interested in how variables effect admission into graduate school. The response variable, admit/don't admit, is a binary variable. 研究者感兴趣的是这些变量是如何影响研究生录取的。相应变量为一个二进制的变量
mydata<-read.csv("https://stats.idre.ucla.edu/stat/data/binary.csv")
dim(mydata)
head(mydata)
install.packages("skimr")
skimr::skim(mydata)
sapply(mydata,sd)
sapply(mydata,mean)
xtabs(~admit+rank,data=mydata)
可选择的分析方法
Logistic regression
Probit regression
OLS regression
Two-group discriminant function analysis
回归拟合
mydata$rank<-factor(mydata$rank)
mylogit<-glm(admit~gre+gpa+rank,data=mydata,family="binomial")
summary(mylogit)
confint(mylogit)
confint.default(mylogit)
newdata1<-with(mydata,data.frame(gre=mean(gre),gpa=mean(gpa),rank=factor(1:4)))
newdata1
newdata1$rankP<-predict(mylogit,newdata=newdata1,type="response")
newdata1
newdata2<-with(mydata,data.frame(gre=rep(seq(from=200,to=800,length.out=100)),
gpa=mean(gpa),
rank=factor(rep(1:4,each=100))))
newdata3_1<-cbind(newdata2,predict(mylogit,newdata=newdata2,type="response"))
head(newdata3_1)
newdata3_2<-cbind(newdata2,predict(mylogit,newdata=newdata2,type="link",se=TRUE))
head(newdata3_2)
newdata3_3<-within(newdata3_2,{
PredictedProb<-plogis(fit)
LL<-plogis(fit-(1.96*se.fit))
UL<-plogis(fit+(1.96*se.fit))
})
head(newdata3_3)
library(ggplot2)
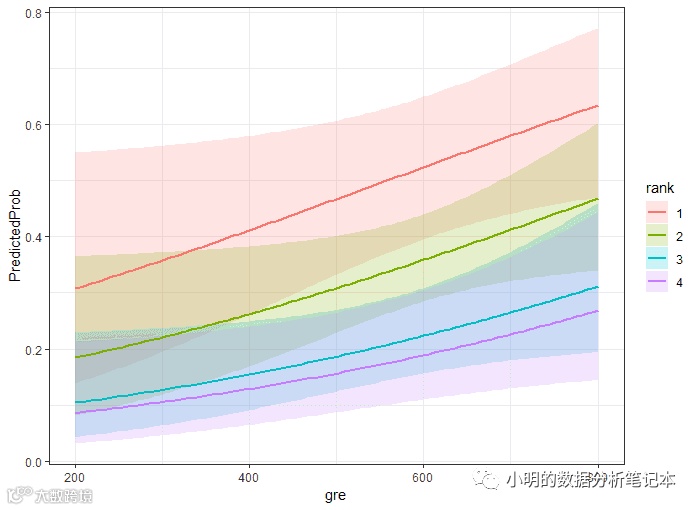
ggplot(newdata3_3,aes(x=gre,y=PredictedProb))+
geom_ribbon(aes(ymin=LL,ymax=UL,fill=rank),alpha=0.2)+
geom_line(aes(colour=rank),size=1)+
theme_bw()
with(mylogit,null.deviance-deviance)
with(mylogit,df.null-df.residual)
with(mylogit,pchisq(null.deviance-deviance,df.null-df.residual,lower.tail=F))
logLik(mylogit)
有的结果还不是很明白
需要把原文再多看几遍
需要抽时间看的内容
apply函数组的用法
with函数的用法
新学到的函数
xtabs()函数
> xtabs(~admit+rank,data=mydata)
rank
admit 1 2 3 4
0 28 97 93 55
1 33 54 28 12
pandas中类似的函数
crosstab
python实现逻辑斯蒂分类回归的例子
http://dblab.xmu.edu.cn/blog/logistic-regression-in-python/
还有很多其他分析的实例
https://stats.idre.ucla.edu/other/dae/
欢迎大家关注我的公众号
小明的数据分析笔记本
