
本文作者:孙晓玲
文字编辑:张馨月
导读
“度娘”告诉我们——“这是一个用数据说话的时代,也是一个依靠数据竞争的时代。世界500强企业中,有90%以上都建立了数据分析部门。IBM、微软、Google等知名公司都积极投资数据业务,建立数据部门,培养数据分析团队。各国政府和越来越多的企业意识到数据和信息已经成为企业的智力资产和资源,数据的分析和处理能力正在成为日益倚重的技术手段。”无疑,数据分析职业成为许多人朝夕拼搏的职业目标。那炙手可热的数据分析职位的薪资待遇如何?各大公司对数据分析职位的基本要求又有哪些?今天,小编就带着这个问题为大家答疑解惑。
一、网站内容分析
本文中,小编将以求职网站“猎聘网”(https://www.liepin.com/zhaopin/?d_sfrom=search_fp_nvbar&init=1)发布的职业招聘信息为例,爬取该网页上有关“数据分析”职业(后简称为“分析师”)的薪资信息(职位、公司、薪资待遇、地区、学历要求、经验要求)。

经过初步观察,输入关键字“数据分析”得到招聘“数据分析”职务400例(每页40例,共10页)。分析网址信息,页数从0计数,为后续写循环做准备。

二、单页分析师薪资信息爬取
使用“copy”命令来获取网页源代码存储在“temp.txt”文本文档,分析我们所需的信息。
cap mkdir "D:\分析师薪资信息"cd " D:\分析师薪资信息"copy "https://www.liepin.com/zhaopin/?compkind=&dqs=&pubTime=&pageSize=40&salary=&compTag=&sortFlag=°radeFlag=0&compIds=&subIndustry=&jobKind=&industries=&compscale=&key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&siTag=ZFDYQyfloRvvhTxLnVV_Qg%7EfA9rXquZc5IkJpXC-Ycixw&d_sfrom=search_industry_jobtitle&d_ckId=a326cad9ae331f135135a824dc7cfde6&d_curPage=0&d_pageSize=40&d_headId=a326cad9ae331f135135a824dc7cfde6&curPage=0" temp.txt, replace
得到源代码后,对文本内容进行分析。
(一)薪资信息获取
首先定位薪资信息,进行观察。

可以发现薪资待遇、地区、学历要求、经验要求都在一个以“title="”开头,以“">”结尾的字符串之间。将文本信息导入Stata软件,使用正则表达式保留满足这个条件的行观测值,就得到包含薪资信息的行,得到结果如图所示。

得到所需信息后,对其进行数据清洗,包括变量一列变多列、重命名、保存备用等操作得到薪资信息如下。

生成id列为后续合并数据创造条件。整个过程所需程序如下:
infix strL v 1-100000 using temp.txt, clearpreservekeep if ustrregexm(v, `"^title="(.*?)">$"')split v, p(`"title=""' "_" `"">"')keep v2-v5rename (v2 v3 v4 v5) (薪资待遇 地区 学历要求 经验要求)gen id=_nsave 薪资.dta,replacerestore
定位公司名称信息,进行观察。

此时公司信息都在包含“<a title="公司”字符串的行。使用正则表达式保留满足这个条件的行观测值,就得到包含公司信息的行,结果如图所示。
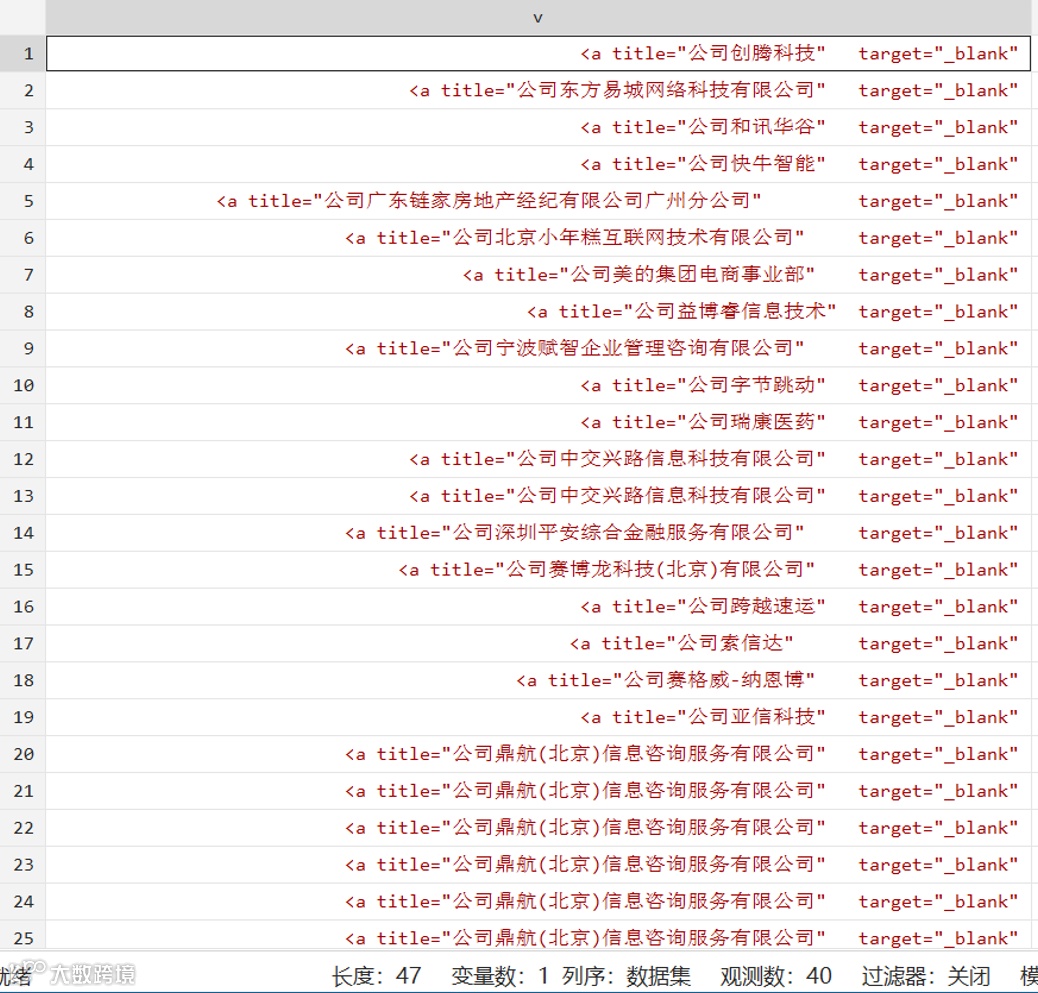
得到所需信息后,对其进行数据清洗,不同于薪资信息,公司名称之前都多出“公司”二字,使用字符串函数“substr”对其进行截取,其他操作同上,得到公司名称信息。

所需程序如下:
preservekeep if ustrregexm(v, `"<a title="公司"')split v, p(`"""')keep v2replace v2=substr(v2,7,.)rename v2 公司gen id=_nsave 公司.dta,replacerestore
(三)职位名称获取
定位职位名称信息,进行观察。

此时职位信息都在包含“<h3 title="招聘”字符串的行。使用正则表达式保留满足这个条件的行观测值,就得到包含职位名称信息的行,得到结果如图所示。

得到所需信息后,对其进行数据清洗,职位名称也多出“招聘”字样,同样使用字符串函数“substr”对其进行截取,其他操作同上,得到职位名称信息。

所需程序如下:
keep if ustrregexm(v, `"<h3 title="招聘"')split v, p(`"""')keep v2replace v2=substr(v2,7,.)rename v2 职位gen id=_nsave 职位.dta,replace
(四)信息合并
使用merge命令合并信息,得到所需信息。

由此就得到单个页面的职位信息,程序如下:
use 职位.dta,clearmerge m:m id using 公司.dtadrop _mmerge m:m id using 薪资.dtadrop id _msave 分析师薪资信息.dta,replace
相比单页面的信息获取,多页面只需再单页面程序的基础上加上循环即可,这里给出程序即结果,过程就不再赘述。
forvalues i = 0 (1) 9 {copy "https://www.liepin.com/zhaopin/?compkind=&dqs=&pubTime=&pageSize=40&salary=&compTag=&sortFlag=°radeFlag=0&compIds=&subIndustry=&jobKind=&industries=&compscale=&key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&siTag=ZFDYQyfloRvvhTxLnVV_Qg%7EfA9rXquZc5IkJpXC-Ycixw&d_sfrom=search_industry_jobtitle&d_ckId=a326cad9ae331f135135a824dc7cfde6&d_curPage=0&d_pageSize=40&d_headId=a326cad9ae331f135135a824dc7cfde6&curPage=`i'" temp.txt, replaceinfix strL v 1-100000 using temp.txt, clearpreservekeep if ustrregexm(v, `"^title="(.*?)">$"')split v, p(`"title=""' "_" `"">"')keep v2-v5rename (v2 v3 v4 v5) (薪资待遇 地区 学历要求 经验要求)gen id=_nsave 薪资.dta,replacerestorepreservekeep if ustrregexm(v, `"<a title="公司"')split v, p(`"""')keep v2replace v2=substr(v2,7,.)rename v2 公司gen id=_nsave 公司.dta,replacerestorekeep if ustrregexm(v, `"<h3 title="招聘"')split v, p(`"""')keep v2replace v2=substr(v2,7,.)rename v2 职位gen id=_nsave 职位.dta,replaceuse 职位.dta,clearmerge m:m id using 公司.dtadrop _mmerge m:m id using 薪资.dtadrop id _msave 分析师薪资信息`i'.dta,replace}
得到10个页面的薪资信息文件。
将10文件进行纵向合并就得到全部薪资信息合集,所得结果如下:

这样,我们就得到“猎聘网”全部“数据分析”职位的薪资信息了。薪资水平哪家强?快来试试吧~

1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。


