
本文作者:张欣怡,中南财经政法大学统计与数学学院
本文编辑:胡艺粼
技术总编:孙一博
Stata and Python 数据分析

在Python中,有很多与序列相关的内置函数,用于处理和分析数据。本文将介绍sorted()、enumerate()、zip()、reversed()等常见内置函数,让我们一起来看看具体的用法吧。
sorted()函数可以对任意序列的元素进行排序,返回一个新的有序序列。
sorted([9,4,5,0])
sorted('python')
利用sorted()函数对可迭代的对象进行排序,并通过参数key确定排序的依据;参数reverse确定升降序的方式,默认为升序排列。
sorted(iterable, /, *, key=None, reverse=False)下面我们来看一个具体的例子,以字典中的键值对key、value作为迭代对象,并按照字典内容value进行排列。
scores={'张三':45,'李四':89,'王五':76}print(sorted(scores.items(),key=lambda i:i[1],reverse=True))
输出结果如下:

需要注意的是我们以scores.items()为迭代对象,可以同时输出字典中的键值对。如果直接将scores作为迭代对象,输出的结果将以字典key值排序,而不是我们所希望的以字典内容value排序。在这个例子中,排序依据为lambda,用i[1]表示value,并按照降序进行排列。
在对象迭代时,enumerate()函数可以对相应对象:迭代器或者列表、元组等序列进行枚举,下标起始位置默认从0开始。
enumerate(sequence,[start=0])以列表为例进行枚举,利用enumerate()返回枚举对象,我们可以改变下标起始位置。
list1 = ['python','and','stata']list2 = list(enumerate(list1,start=1))#下标起始位置为1list2

索引数据时,通过enumerate返回序列所映射位置的值,一般通过for循环实现,可以同时获得索引和值。
lists = ['python','and','stata']dicts = { }for i,values in enumerate(lists):dicts[values] = idicts

num = len(open(filepath,'r').read.lines())num = 0for i,lines in enumerate(open(filepath,'r')):num += 1
上述两种方法均可以用于统计文件中的行数。不同的是第一种方法虽然简单,但是运行速度较慢,而使用enumerate()函数可以解决这种缺陷。第二种方法借助内置函数实现快速统计,适用于文件较大的情况。
zip()函数可以将迭代对象作为参数,该迭代对象可以是Python中的数据结构,例如元组、列表、字典、集合。
zip(*iterables)zip()函数将多个序列对组合成一个新的序列,聚合传入每个序列中相同位置的元素。
list1 = ['爬虫','python']list2 = ['俱乐部','stata']list(zip(list1,list2))
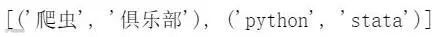
list3 = [0,1,2,3,4]list4 = [7,8,9]list5 = ['python','stata']list(zip(list3,list4,list5))

使用zip()函数时,序列中元素的个数取决于最短的序列,且可以同时组合多个序列。在这个例子中,我们利用zip()函数将三个列表组合成一个新的列表,且列表中元素的个数为2,这取决于最短的列表list5。
下面以学生信息管理的例子介绍zip()函数的实际应用。
def studentInformation():students=[]id_student=input('请输入学号:')name_student=input('请输入姓名:')gender_student=input('请输入性别:')id_list=id_student.split(' ')name_list=name_student.split(' ')gender_list=gender_student.split(' ')information=zip(id_list,name_list,gender_list)for values in information:dictinfo={'学号':values[0],'姓名':values[1],'性别':values[2]}students.append(dictinfo)passfor values in students:print(values)pass
studentInformation()请输入学号:10 11 12请输入姓名:张三 李四 王五请输入性别:男 女 男
输出结果为:

运行上述程序,我们需要分别输入学号、姓名、性别等信息并形成相关的列表,使用zip()函数将这些列表组合,结合循环语句就能够输出我们想要的每一个学生信息。
reversed()函数可以从后向前迭代,对序列中的元素进行反向排序,一般用于需要翻转的序列。
reversed(sequence, /)可以转换的序列包括列表、元组、字符串和range()函数。
#列表list(reversed([1,2,3,4,5]))#元组list(reversed((6,7,8,9,10)))#字符串list(reversed('string'))#range()list(reversed(range(10)))
输出结果为:

reversed()函数同样可以应用于for循环来迭代序列。
list1 = [1,2,3,4,5]for list2 in reversed(list1):print(list2)
输出结果为:

以上与序列相关的内置函数根据各自的定义,可以结合使用。
例如,zip()可以和enumerate()结合使用,同时迭代多个序列:
list1 = ['爬虫','python']list2 = ['俱乐部','stata']for i,(a,b) in enumerate(zip(list1,list2)):print(i,a,b)

使用zip()将range()和reversed()生成的内容组合:
dicts = dict(zip(range(5),reversed(range(10))))dicts

如果我们需要将两个列表合并,同时进行排序,就可以将zip()与sorted()结合使用:
list1=[4,2,1,3]list2=['d','c','b','a']sorted(zip(list1,list2)) #按照list1进行排序

以上是对sorted()、enumerate()、zip()、reversed()等常见内置函数的介绍,大家一起灵活应用起来吧。

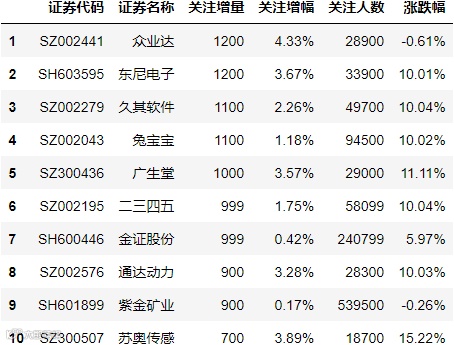
最后,我们为大家揭秘雪球网(https://xueqiu.com/)最新所展示的沪深证券和港股关注人数增长Top10。

对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
“挂羊头卖狗肉”?
cnmapsearch——离公司最近的快餐店在哪
微信公众号“Stata and Python数据分析”分享实用的Stata、Python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
武汉字符串数据科技有限公司一直为广大用户提供数据采集和分析的服务工作,如果您有这方面的需求,请发邮件到statatraining@163.com,或者直接联系我们的数据中台总工程司海涛先生,电话:18203668525,wechat: super4ht。海涛先生曾长期在香港大学从事研究工作,现为知名985大学的博士生,爬虫俱乐部网络爬虫技术和正则表达式的课程负责人。
此外,欢迎大家踊跃投稿,介绍一些关于Stata和Python的数据处理和分析技巧。
投稿邮箱:statatraining@163.com投稿要求:1)必须原创,禁止抄袭;2)必须准确,详细,有例子,有截图;注意事项:1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

