
横断面调查(cross-sectional study),也称为患病率调查(prevalence study),是医学领域中常见的观察性研究方法,也是其他分析流行病学研究的基础,为分析性研究中待检验的疾病因果关系提出初步假设。通常使用普查和抽样调查方法,在某个人群中收集特定时间内有关疾病与健康状况的资料,描述疾病或健康状况在地区、时间和人群中的分布规律以及观察某些因素与疾病之间的关联。横断面研究特征如下表所示。

横断面研究的主要研究方法包括普查和抽样调查两种,应根据不同研究目的选择,选择合适的研究方法。横断面研究两种方法的特征如下表所示。

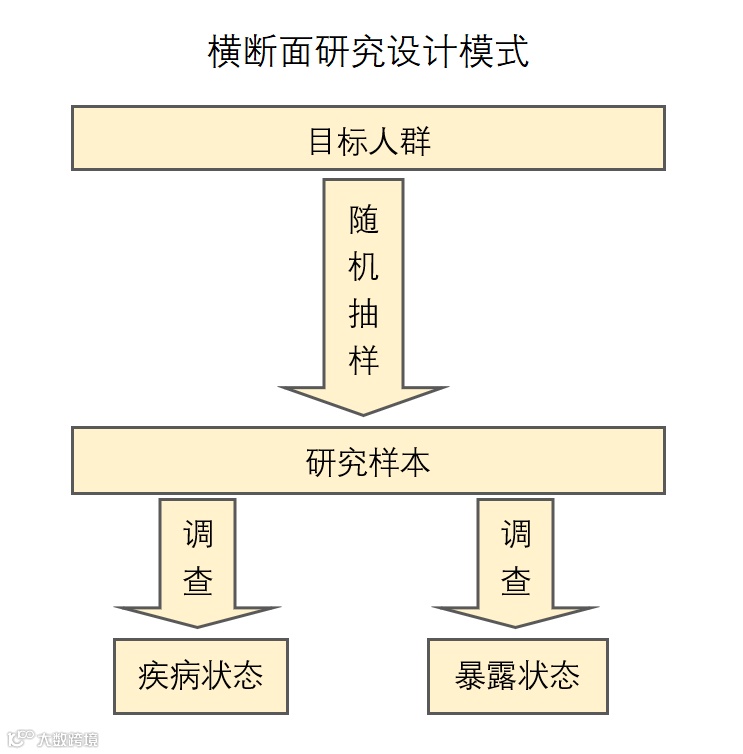
使用抽样调查方法开展横断面研究基本按照以下设计模式进行。
样本量计算
当我们使用抽样调查方法开展横断面研究时,研究对象(即样本人群)的选择首先取决于研究目的;其次则是样本的代表性,在质量方面,随机抽样是样本代表总体的有力保证,在数量方面,足够的样本含量是样本代表总体的有效措施。开始收集相关资料之前,估计样本含量是必不可少的步骤。样本含量估计要考虑三点因素:
①总体标准差平均水平σ的高低,其值越大,所需样本含量越大,一般从以往的研究资料或预调查获得。
②容许误差δ,即对调查要求的精确性。
③确定控制容许误差的概率,即显著性水准α,其值越小,可靠性越好,所需样本含量也越大,通常取0.05。
横断面研究样本含量计算方法按不同抽样方法各异。以下主要介绍横断面研究单纯随机抽样样本量计算。根据不同资料类型,使用不同的估计方法。
一、估计总体率所需的样本含量

二、估计总体均数所需的样本含量

公式(1)中,α为显著性水平,一般设为0.05,μα/2值为时对应的标准正态分布曲线下的面积;π为总体率的标准差;δ为容许误差。公式(2)中,为σ总体均数标准差。
无限总体抽样按公式(1),(2)求n,有限总体还需要使用以下校正公式(3)进行校正;公式(3)中N是有限总体包含的单位数。当n/N<0.05时,可省去以下校正。

案例应用
(一)估计总体率样本含量
为了解某城镇妇女生育率情况,根据现有资料,我国妇女现阶段高龄生育率在0.29上下波动,容许误差定位0.01,α=0.05,估计高龄妇女样本含量。
我们使用公式(1)计算样本量:
![]()
结果可得,样本含量需要7910人。
(二)估计总体均数样本含量
某化工厂共有5000名工人,为了解该厂职工白细胞数的平均水平,评价该厂生产条件是否对白细胞数有影响,根据以往资料,职工白细胞总数的标准差为0.95×109/L,希望控制误差不超过0.1×109/L,取α=0.05,问需调查多少人。
我们使用公式(2)计算样本量,由于n/N>0.05,需使用校正公式(3)进行校正:

结果可得,样本含量需要325人。
参考来源:
1.孙振球,徐勇勇.医学统计学:第4版[M].北京:人民卫生出版社.2014.
制作:吴君乐
初审:何冠豪、胡建雄、龚德鑫
审核:肖建鹏、刘涛
指导:马文军


关于我们
邮箱:statisic@gdiph.org.cn
微信号:gdiph-stat



