
最近无意看到一份关于数据分析的Python笔试题,做起来还是很有意思的,特意自己动手做了一下,和大家分享一下,希望大家也可以跟着练习。
题目如下:


首先,模拟数据:
import pandas as pd
import numpy as np
df = pd.DataFrame({'order_no':['order_18213','order_16061','order_10176','order_11923','order_18791',
'order_12534','order_14502','order_14488', 'order_15488','order_18118'],
'province':['山东','四川','福建','广东','广东','广东','广东','山东','湖南','福建'],
'gender':['女','女','女','女','男','女','男','男','女','女'],
'age':[29.0,27.0,25.0,25.0,np.nan,27.0,25.0,27.0,np.nan,27.0],
'education':['本科','研究生','本科','研究生','研究生','本科','大专','大专','本科','大专'],
'overdue_days':[0,17,0,0,12,20,22,32,0,2],
'info_label':[0,1,0,0,1,1,1,1,0,1]
})
df

df['gender']=df['gender'].map({'男':1,'女':0})
df['gender']=df['gender'].replace(['男','女'],[1,0])
df.loc[df['gender']=='男','gender']=1
df.loc[df['gender']=='女','gender']=0df

# 使用fillna()填补缺失值即可
df_mean = df['age'].mean()
df['age'].fillna(df_mean,inplace=True)
df

# 逾期率=逾期客户/全部客户
# 计算各省的逾期用户
df_overdue = df.groupby('province')['info_label'].sum().reset_index()
df_overdue.columns=['province','overdue_cnt']
# 计算各省的用户数
df_all = df.groupby('province')['info_label'].count().reset_index()
df_all.columns=['province','all_cnt']
# 合并各省逾期用户及各省用户数形成新的报表df1
df1 = pd.merge(df_overdue, df_all, on = ['province'], how = 'left')
# 得到各省的逾期率
df1['overdue_pec'] = df1['overdue_cnt']/df1['all_cnt']
df1

题目4:计算广东省男性用户的逾期率
# 计算广东省的逾期男性用户
overdue_pec_gd = df[(df['province']=='广东') & (df['gender'] == 1)]['info_label'].sum()/df[(df['province']=='广东') & (df['gender'] == 1)]['info_label'].count()
print(overdue_pec_gd)
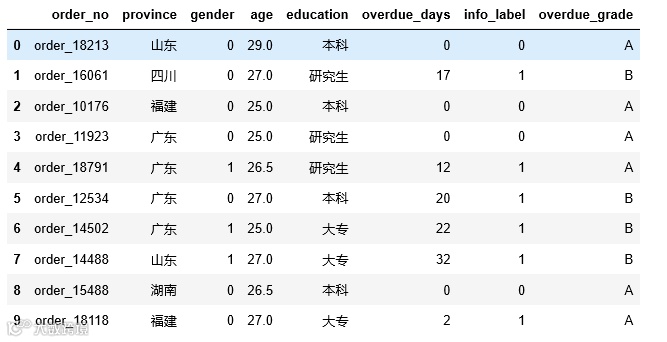
df['overdue_grade'] = df['overdue_days'].apply(lambda x: 'A' if x<15 else 'B')
df
# 使用get_dummies()进行one-hot变量,然后进行数据合并concat(),删除使用drop()
df=pd.concat((df,pd.get_dummies(df['education'])),axis=1)
df.drop(['education'],axis=1)
结果如下:


1.回复“PY”领取1GB Python数据分析资料
2.回复“BG”领取5GB 名企数据分析报告