

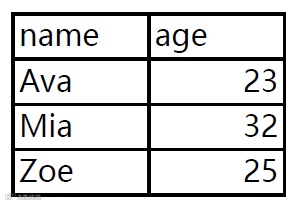



1import pdfplumber
2import pandas as pd
3
4# 创建一个空数据框
5df = pd.DataFrame()
6
7# 使用with语句打开pdf文件
8with pdfplumber.open("D:\\python\\cai\\5.pdf") as pdf:
9 # 使用for循环遍历每个pages
10 for page in pdf.pages:
11 # 取出当前页表格,结果为列表
12 d=page.extract_table()
13 # 将列表转为数据框
14 df1 = pd.DataFrame(d[1:], columns=d[0])
15 #添加至df数据框中
16 df = df.append(df1)


如果你在跟着学习,请在留言区留言:打卡
如果你刚看到本文,可以查看本系列历史文章跟着学习:
跟小白学Python数据分析——Anaconda安装
跟小白学Python数据分析——使用spyder
跟小白学Python数据分析——数据导入1
跟小白学Python数据分析——数据导入2

1.回复“PY”领取1GB Python数据分析资料
2.回复“BG”领取5GB 名企数据分析报告