
小伙伴们好!上次给大家介绍过关联分析的定义和原理。
想要复习的同学请点击以下链接:
今天,我们就来说说怎么用R语言实现Apriori关联分析。首先,安装R包“arules”. 这个包就是专门用于关联分析的:Mining Association Rules and Frequent Itemsets。
install.packages("arules")library(arules)
第一步,构建关联数据,注意!关联数据必须是一个list类型。data.frame,matrix等都不适合。
a_list <- list(c("a","b","c"),c("a","b"),c("a","b","d"),c("c","e"),c("a","b","d","e"))

这只是随机生成的一个示例数据,可以看出这个数据的基本结构,一共有5条信息,每条信息可以看作一个客人的购买记录,有人只买了ab两个商品,有的搭配了abc或者abd各种组合。
接下来,我们还需要设置每一条信息的名字。我们简单命名为Tr1-Tr5。
## Set transaction namesnames(a_list) <- paste("Tr",c(1:5), sep = "")
第二步,运用arules里的transaction功能生成关联数据集。到这里,关联数据准备工作就完成了。
# Use the constructor to create transactionstrans1 <- transactions(a_list)trans1

第三步,基于Apriori算法,探索关联规则。
rules <- apriori(trans1)
以上采用的是默认参数,筛选出所有规则,一共有19个规则。但有一些规则可能支持度、置信度较低,其实不是我们想要筛选的对象,这时我们可以通过supp与conf两个参数,来设定最小支持度、最小置信区间。
rules <- apriori(a_list,parameter = list(supp = 0.5, conf = 0.9, target = "rules"))summary(rules)
第四步,显示关联规则结果。
inspect(rules)
所有规则是按支持度support从大到小的顺序排列。根据业务需求,也可以按置信度confidence排列。可以看到,除了单独出现的a、b, 第三个支持度较高的规则是d与b同时出现,支持度为0.4。
到这一步,关联规则的分析已经可以报告结果了。但以上规则可能不够直观,那么,我们来进行可视化展示吧!
第五步,可视化。需要用到的R包是arulesViz。
install.packages("arulesViz")library("arulesViz")plot(rules)
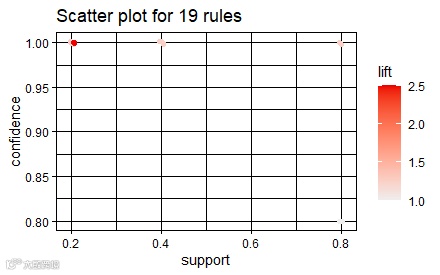
plot(rules, method = "grouped")
以上就是Apriori关联分析的内容。感兴趣的小伙伴可以找一个R语言内置的数据集(推荐“Groceries”),或者自己创建一个list,有空分析一下,对代码真正熟悉起来。
每天进步一点点,我们一起加油!觉得有帮助可以分享给更多的小伙伴。别忘了右下角点个“在看”哦!