
微信添加CDA为好友(ID:joinlearn),拉你入500人数据分析师交流群,点击阅读原文可查看CDA数据分析师交流群规范与福利,期待你来~
本文摘要自Web Scraping with Python – 2015
书籍下载地址:https://bitbucket.org/xurongzhong/python-chinese-library/downloads
源码地址:https://bitbucket.org/wswp/code
演示站点:http://example.webscraping.com/
演示站点代码:http://bitbucket.org/wswp/places
推荐的python基础教程: http://www.diveintopython.net
HTML和JavaScript基础:
http://www.w3schools.com
web抓取简介
为什么要进行web抓取?
网购的时候想比较下各个网站的价格,也就是实现惠惠购物助手的功能。有API自然方便,但是通常是没有API,此时就需要web抓取。
web抓取是否合法?
抓取的数据,个人使用不违法,商业用途或重新发布则需要考虑授权,另外需要注意礼节。根据国外已经判决的案例,一般来说位置和电话可以重新发布,但是原创数据不允许重新发布。
更多参考:
http://www.bvhd.dk/uploads/tx_mocarticles/S_-_og_Handelsrettens_afg_relse_i_Ofir-sagen.pdf
http://www.austlii.edu.au/au/cases/cth/FCA/2010/44.html
http://caselaw.findlaw.com/us-supreme-court/499/340.html
背景研究
robots.txt和Sitemap可以帮助了解站点的规模和结构,还可以使用谷歌搜索和WHOIS等工具。
比如:http://example.webscraping.com/robots.txt

更多关于web机器人的介绍参见 http://www.robotstxt.org。
Sitemap的协议: http://www.sitemaps.org/protocol.html,比如:

站点地图经常不完整。
站点大小评估:
通过google的site查询 比如:site:automationtesting.sinaapp.com
站点技术评估:

分析网站所有者:

抓取第一个站点
简单的爬虫(crawling)代码如下:

可以基于错误码重试。HTTP状态码:https://tools.ietf.org/html/rfc7231#section-6。4**没必要重试,5**可以重试下。
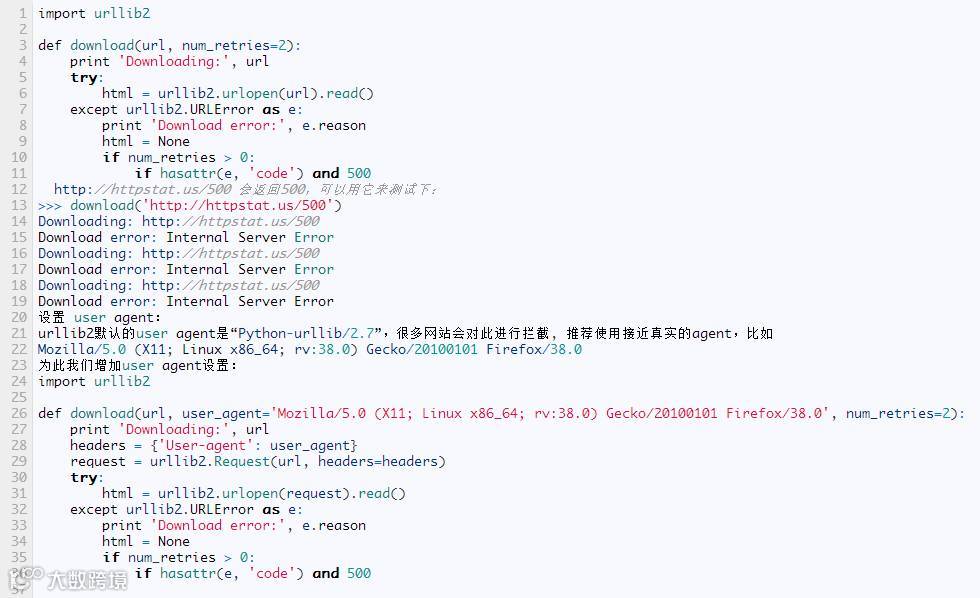


维护成本比较高。
Beautiful Soup:

完整的例子:

Lxml基于 libxml2(c语言实现),更快速,但是有时更难安装。网址:http://lxml.de/installation.html。

lxml的容错能力也比较强,少半边标签通常没事。
下面使用css选择器,注意安装cssselect。

在 CSS 中,选择器是一种模式,用于选择需要添加样式的元素。
“CSS” 列指示该属性是在哪个 CSS 版本中定义的。(CSS1、CSS2 还是 CSS3。)
选择器 |
例子 |
例子描述 |
CSS |
.class |
.intro |
选择 class=”intro” 的所有元素。 |
1 |
#id |
#firstname |
选择 id=”firstname” 的所有元素。 |
1 |
* |
* |
选择所有元素。 |
2 |
element |
p |
选择所有元素。 |
1 |
element,element |
div,p |
选择所有 元素和所有元素。 |
1 |
element element |
div p |
选择 元素内部的所有元素。 |
1 |
element>element |
div>p |
选择父元素为 元素的所有元素。 |
2 |
element+element |
div+p |
选择紧接在 元素之后的所有元素。 |
2 |
[attribute] |
[target] |
选择带有 target 属性所有元素。 |
2 |
[attribute=value] |
[target=_blank] |
选择 target=”_blank” 的所有元素。 |
2 |
[attribute~=value] |
[title~=flower] |
选择 title 属性包含单词 “flower” 的所有元素。 |
2 |
[attribute|=value] |
[lang|=en] |
选择 lang 属性值以 “en” 开头的所有元素。 |
2 |
:link |
a:link |
选择所有未被访问的链接。 |
1 |
:visited |
a:visited |
选择所有已被访问的链接。 |
1 |
:active |
a:active |
选择活动链接。 |
1 |
:hover |
a:hover |
选择鼠标指针位于其上的链接。 |
1 |
:focus |
input:focus |
选择获得焦点的 input 元素。 |
2 |
:first-letter |
p:first-letter |
选择每个元素的首字母。 |
1 |
:first-line |
p:first-line |
选择每个元素的首行。 |
1 |
:first-child |
p:first-child |
选择属于父元素的第一个子元素的每个元素。 |
2 |
:before |
p:before |
在每个元素的内容之前插入内容。 |
2 |
:after |
p:after |
在每个元素的内容之后插入内容。 |
2 |
:lang(language) |
p:lang(it) |
选择带有以 “it” 开头的 lang 属性值的每个元素。 |
2 |
element1~element2 |
p~ul |
选择前面有元素的每个 元素。 |
3 |
[attribute^=value] |
a[src^="https"] |
选择其 src 属性值以 “https” 开头的每个元素。 |
3 |
[attribute$=value] |
a[src$=".pdf"] |
选择其 src 属性以 “.pdf” 结尾的所有 元素。 |
3 |
[attribute*=value] |
a[src*="abc"] |
选择其 src 属性中包含 “abc” 子串的每个 元素。 |
3 |
:first-of-type |
p:first-of-type |
选择属于其父元素的首个元素的每个 元素。 |
3 |
:last-of-type |
p:last-of-type |
选择属于其父元素的最后元素的每个 元素。 |
3 |
:only-of-type |
p:only-of-type |
选择属于其父元素唯一的元素的每个 元素。 |
3 |
:only-child |
p:only-child |
选择属于其父元素的唯一子元素的每个元素。 |
3 |
:nth-child(n) |
p:nth-child(2) |
选择属于其父元素的第二个子元素的每个元素。 |
3 |
:nth-last-child(n) |
p:nth-last-child(2) |
同上,从最后一个子元素开始计数。 |
3 |
:nth-of-type(n) |
p:nth-of-type(2) |
选择属于其父元素第二个元素的每个 元素。 |
3 |
:nth-last-of-type(n) |
p:nth-last-of-type(2) |
同上,但是从最后一个子元素开始计数。 |
3 |
:last-child |
p:last-child |
选择属于其父元素最后一个子元素每个元素。 |
3 |
:root |
:root |
选择文档的根元素。 |
3 |
:empty |
p:empty |
选择没有子元素的每个元素(包括文本节点)。 |
3 |
:target |
#news:target |
选择当前活动的 #news 元素。 |
3 |
:enabled |
input:enabled |
选择每个启用的 <input>元素。 |
3 |
:disabled |
input:disabled |
选择每个禁用的 <input>元素 |
3 |
:checked |
input:checked |
选择每个被选中的 <input>元素。 |
3 |
:not(selector) |
:not(p) |
选择非<p>元素的每个元素。 |
3 |
::selection |
::selection |
选择被用户选取的元素部分。 |
3 |
CSS 选择器参见:http://www.w3school.com.cn/cssref/css_selectors.ASP 和 https://pythonhosted.org/cssselect/#supported-selectors。
下面通过提取如下页面的国家数据来比较性能:

比较代码:


Windows执行结果:

Linux执行结果:

其中 re.purge() 用户清正则表达式的缓存。
推荐使用基于Linux的lxml,在同一网页多次分析的情况优势更为明显。
来源 | 磁石针的博客
点击阅读原文可查看CDA数据分析师交流群规范与福利
