
IBM专业成熟的数据挖掘平台IBM SPSS Modeler 18.0版本于2016年3月15日正式发布,这次新版本的发布主要在三个方面做了增强和改进,如下图:

在Modeler 中直接运行大数据算法
在之前的版本中,支持分布式计算的算法需要SPSS Analytics Server这一产品模块才能运行(有了解SPSS的朋友应该知道,SPSS Analytics Server是专门连接Hadoop数据源的服务器),而在IBM SPSS Modeler设计面板上,有专门提供给SPSS Analytics Server的算法,如下图

Analytics Server面板上的所有算法
在最新的18版本中,这些算法不仅支持连接Hadoop的分布式计算,还支持在 Modeler 客户端以及 服务器上运行,因为在新版本中,在Modeler客户端及服务器上,集成了基于内存的分布式算法,在大数据集的处理上,可以更好的提升性能。
所有新算法支持多线程计算
我们都知道,多线程计算可以大大提高计算性能,在以前版本中,支持多线程的算法只包含:CHAID, C&R Tree, QUEST, Linear 和 Neural Network,而在最新版本中,Analytics Server面板上的所有算法都支持多线性计算,因此选用这些算法,可以带来更好的性能提升体验,而且单纯客户端就可以支持,当然了,如果是企业级应用,还是建议使用服务器会更好。
所有新算法的改进与增强
Analytics Server面板上的所有算法都在不同程度上做了改进与增强,比如Tree-AS 和LSVM在算法中封装了数据准备的功能,包括对数据离散化、对超过500字段的输入进行筛选、对日期/时间字段的转换等等; 对Random Trees算法,可以指定要用于分割的预测变量数,以及是否选择“当不再提高准确性时停止构建”等等。
对开源算法的扩展与增强
拥抱开源是IBM当前致力专注做的事情,在IBM SPSS Modeler中,从15版本开始集成 R,到16版本集成Python,到17版本集成Spark,都是最大限度地把开源平台的优势集成到我们的产品中来,那么在最新版本里面,集成Spark不再需要SPSS Analytics Server了,也就是说在IBM SPSS Modeler客户端或服务器,就可以充分利用Spark的内存计算,以及Spark上开源的机器学习算法。以上功能是通过定制对话框构建程序来实现的。

提供强大的扩展功能
在最新版本中,提供了R与Python的扩展,除了上面讲的定制对话框构建程序面板,自己写R或Python语言来实现,还提供了已经定制好的R或Python扩展模块,来直接载入需要的功能,比如地理空间的应用、是否节假日日期数据的载入、读取JSON文件 、IBM云平台BlueMix上Watson分析、连接Cloudant应用等22个应用。
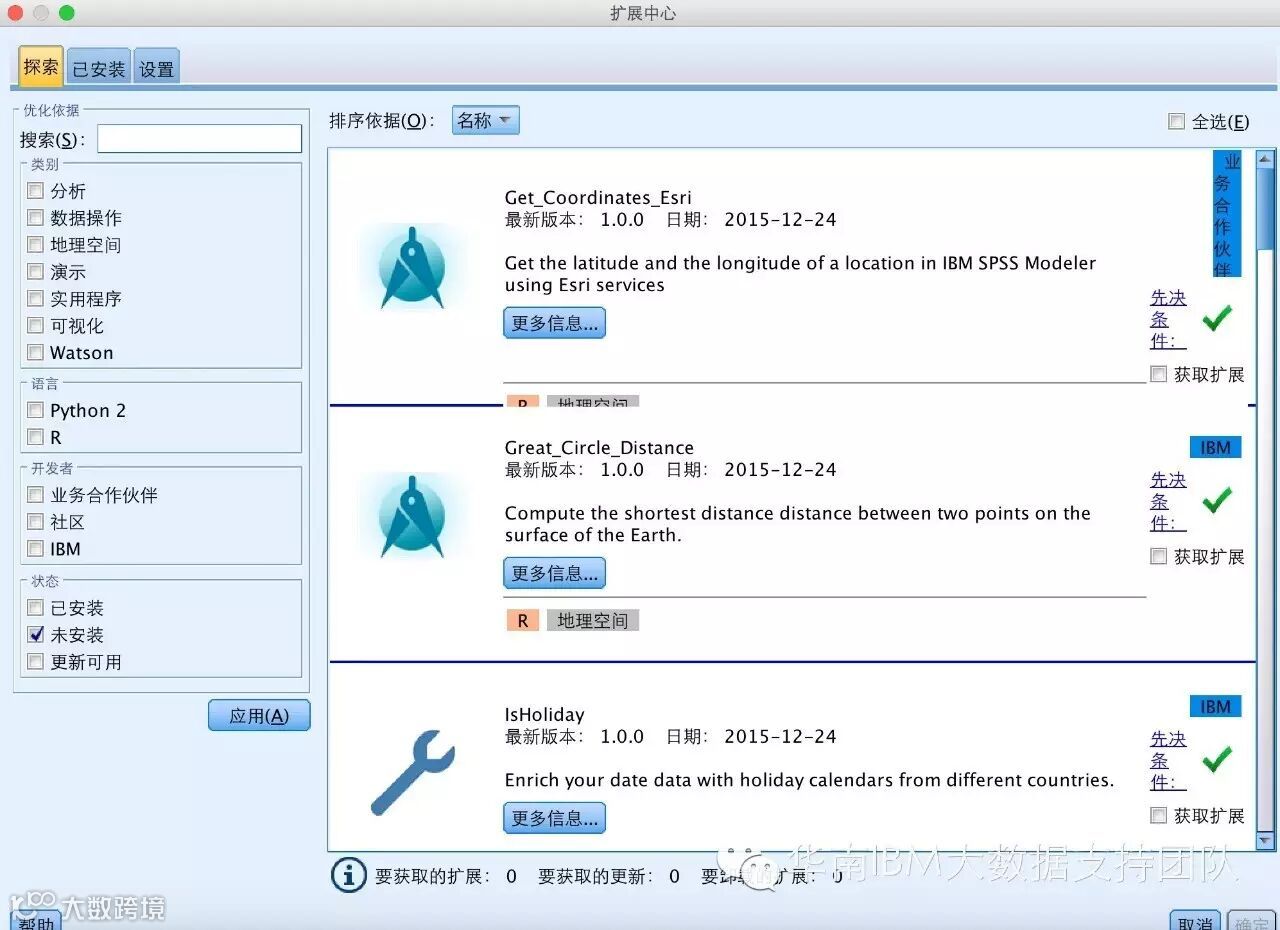
选择获取扩展之后,会自动安装相应的功能,在IBM SPSS Modeler客户端的节点位置会新增相应的应用节点,比如我安装了Cloudant数据源节点,那么在下方会显示Cloudant节点,双击后,可以看到需要配置的相应内容,设置后就可以直接连接Cloudant数据库了,非常方便。

这些扩展是在IBM DevelopWorks Developer Centers网站GitHub (https:/ibmpredictiveanalytics.github.io/)上已经开发好的应用。

相信以后这些应用会越来越多,我们要使用的时候也会越来越方便。
平台支持更广泛
以前的版本中,IBM SPSS Modeler客户端只支持Windows操作系统,而现在的最新版本,可以支持Mac操作系统了,因此喜欢使用苹果电脑的朋友,不再需要安装个虚机来使用IBM SPSS Modeler了,现在可以直接安装使用,界面跟在Windows操作界面上一样的友好。

感兴趣的朋友,赶紧体验一下吧!在IBM官网上可以下载免费试用版! 赶快行动吧!GO! GO! GO!