
微信添加CDA为好友(ID:joinlearn1),拉你入500人数据分析师交流群,点击阅读原文可查看CDA数据分析师交流群规范与福利,期待你来~
文 | cambridgecoding
翻译 | ictar
现今,推荐系统被用来个性化你在网上的体验,告诉你买什么,去哪里吃,甚至是你应该和谁做朋友。人们口味各异,但通常有迹可循。人们倾向于喜欢那些与他们所喜欢的东西类似的东西,并且他们倾向于与那些亲近的人有相似的口味。推荐系统试图捕捉这些模式,以助于预测你还会喜欢什么东西。电子商务、社交媒体、视频和在线新闻平台已经积极的部署了它们自己的推荐系统,以帮助它们的客户更有效的选择产品,从而实现双赢。




用户-产品协同过滤: “喜欢这个东西的人也喜欢……”
产品-产品协同过滤: “像你一样的人也喜欢……”









def predict(ratings, similarity, type='user'):
if type == 'user':
mean_user_rating = ratings.mean(axis=1)
#You use np.newaxis so that mean_user_rating has same format as ratings
ratings_diff = (ratings - mean_user_rating[:, np.newaxis])pred = mean_user_rating[:, np.newaxis] + similarity.dot(ratings_diff) / np.array([np.abs(similarity).sum(axis=1)]).T
elif type == 'item':
pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])
return pred




U是一个(m x r)正交矩阵
S是一个对角线上为非负实数的(r x r)对角矩阵
V^T是一个(r x n)正交矩阵



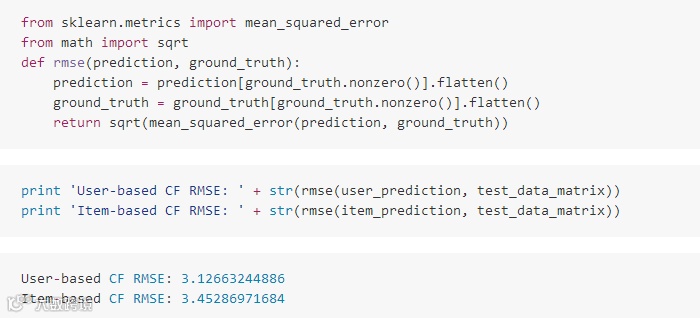
在这篇文章中,我们讲了如何实现简单的协同过滤方法,包括基于内存的CF和基于模型的CF。
基于内存的模型是基于产品或用户之间的相似性,其中,我们使用余弦相似性。
基于模型的CF是基于矩阵分解,其中,我们使用SVD来分解矩阵。
构建在冷启动的情况下(其中,对于新用户和新产品来说,数据不可用)表现良好的推荐系统仍然是一个挑战。标准的协同过滤方法在这样的设置下表现不佳。在接下来的教程中,你将深入研究这一问题。
原文链接:
http://online.cambridgecoding.com/notebooks/eWReNYcAfB/implementing-your-own-recommender-systems-in-python-2
译文链接:https://github.com/ictar/pythondocument/blob/master/Science%20and%20Data%20Analysis/在Python中实现你自己的推荐系统.md
点击阅读原文可查看CDA数据分析师交流群规范与福利
