


作者 张俊红
本文为 CDA 志愿者张俊红,转载需授权
01|明确本次爬虫以及目的:
我是想看看太原的房地产情况,包括楼盘名称、价格、所处区域、评论数(一定程度上可以反映出该楼盘受欢迎程度)。
明确了目的以后就该去寻找这些数据的出处,也就是网站,由于太原互联网环境欠发达,所以好多房产APP上都没有太原,有的APP有,但是也只有几十家楼盘,最后在搜索的过程中锁定了房天下。这个楼盘数量还是可以的,也有我们需要的数据,所以就他了。


02|目标网页分析:
通过查看网页,我们知道目标数据存储在 17 页中,这就不是普通的静态网页爬取,这种需要翻页的数据爬取,我们一般有两种方法:一是通过修改url参数进行网页的切换,二是通过调用selenium模拟浏览器进行下一页的点击。



上面两个截图一个是17页,一个是9页对应的url,我们发现在参数上并没有明确的规律,看来利用修改参数的方法是行不通了,只能使用selenium,在使用selenium实现的过程中,我无意间发现了事情:

在进行元素审查时,我发现页面对应的href,即链接网站是有规律的,而且不是那么杂乱无章的,我就把href里面的对应链接粘贴到搜索框,发现真能跳转到相应的页面,看来是不需要使用selenium了,用修改参数的方法进行循环即可。
03|数据的抓取:
#导入常用的库
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
#建立a,b,c,d四个空列表用来存放一会抓取到的数据
a_name=[]
b_adress=[]
c_price=[]
d_comment_value=[]
#开始url参数循环,即网页的循环
for i in range(1,18):
url="http://newhouse.taiyuan.fang.com/house/s/b9"+str(i)+"/"
html=requests.get(url)
html.encoding="GBK"#解决中文乱码问题
soup = BeautifulSoup(html.text, 'lxml')#使用lxml解析方式
#开始抓取楼盘名称的循环
first=soup. find_all(class_='nlcd_name')#抓取class属性为=“nlcd_name”对应的内容
for name in first:#依次取出first里面的每一条内容
name1=name.find_all("a")#把从first里面取出来的内容进行再次查找其中a标签的内容
for name2 in name1:#依次取出name1里面的每一条内容name2
a_name.append(name2.get_text().strip())#通过get_text()获取name2的内容,并添加到a_name列表里面。
print (i,len(a_name))#打印出每一次循环以后a_name列表的长度,每一次循环对应一页的内容,该长度代表每一页抓取到的数量
#开始抓取楼盘地处区域的循环
Adress=soup. find_all(class_="address")
for adress in Adress:
for adress1 in adress.select("a"):#通过select选择器选择adress里面的a标签。
b_adress.append(adress1.text.strip()[0:5].strip()) print (i,len(b_adress))
#开始抓取楼盘价格的循环,循环注释与前面类似
Price=soup. find_all(class_="nhouse_price")
for price in Price:
for price1 in price.select("span"):
c_price.append(price1.get_text())
print (i,len(c_price))
#开始抓取楼盘对应评论数量的循环,循环注释与前面类似
value_num=soup. find_all(class_='value_num')
for num1 in value_num:
d_comment_value.append(num1.get_text()[1:-4])
print (i,len(d_comment_value))| 页数 | 获取数据个数 |
|---|---|
| 1 | 20 |
| 1 | 20 |
| 1 | 19 |
| 1 | 20 |
| —— | —— |
| 9 | 180 |
| 9 | 180 |
| 9 | 179 |
| 9 | 178 |
| —— | —— |
| 9 | 180 |
| 9 | 180 |
| 9 | 179 |
| 9 | 178 |
| —— | —— |
| 17 | 334 |
| 17 | 334 |
| 17 | 330 |
| 17 | 328 |
上述表格为部分页数对应的数据个数,按理来说,每一页不同的指标之间的个数是相同的,而实际是不同的,说明每一页抓取到的个别指标有缺失。我们具体去看看有缺失的页数。

通过观察发现,第一页中确实有一个楼盘的价格缺失。我们需要对缺失值进行填充处理。因为必须保证楼盘、区域、价格、评论数一一对应,所以我们采取向指定的确实位置插入值。
#向c_price列表中指定位置插入值c_price.insert(0,"价格待定")
c_price.insert(252,"价格待定")
c_price.insert(253,"价格待定")
c_price.insert(254,"价格待定")
#向d_comment_value列表中指定位置插入值
d_comment_value.insert(167,"0")
d_comment_value.insert(174,"0")
d_comment_value.insert(259,"0")
d_comment_value.insert(260,"0")
d_comment_value.insert(316,"0")
d_comment_value.insert(317,"0")04|数据分析:
DataFrame表生成
data={"name":a_name,"adress":b_adress,"price":c_price,"comment_num":d_comment_value}#生成字典
house=pd.DataFrame(data)#创建DataFrame对象
house.head(5)

数据预处理
#值替换,将汉字替换成拼音便于后续处理
house.replace(["[万柏林]","[小店]","[尖草坪]","[晋源]"],
["wanbailin","xiaodian","jiancaoping","jinyuan"],inplace=True)
house.replace(["[杏花岭]","[迎泽]"],
["xinghualing","yingze"],inplace=True)
house.replace(["[榆次]","晋中","[阳曲]","马来西亚柔"],"other",inplace=True)
house.replace("价格待定",0,inplace=True)
#值类型转换,便于进行数值运算
house.comment_num=house.comment_num.astype(int)
house.price=house.price.astype(float)数据分析
adress分析
house.groupby("adress").count()["name"]/334*100#将数据按楼盘所处位置进行分组#绘制各地区楼盘占比的饼图
labels = 'xiao_dian', 'wan_bai_lin','xing_hua_ling', 'jian_cao_ping', 'ying_ze','jin_yuan','other'
sizes = [34.73, 20.96, 10.78, 8.98,8.98,8.68,6.89]
colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral','red','pink','blue']
plt.pie(sizes,labels=labels,colors=colors,
autopct='%1.1f%%', shadow=True, startangle=90)
| 代号 | 地区 |
|---|---|
| xiao_dian | 小店区 |
| wan_bai_lin | 万柏林区 |
| xing_hua_ling | 杏花岭区 |
| jian_cao_ping | 尖草坪区 |
| ying_ze | 迎泽区 |
| jin_yuan | 晋源区 |
| other | 清徐、古交、娄烦 |
通过数据可以发现,小店区的楼盘数量占比最多为34.7%,其次依次为:万柏林区、杏花岭区、尖草坪区、迎泽区、晋源区、其他
comment_num分析
house.sort_index(by="comment_num",ascending=False).head(10)#按评论数进行排序,挑选出评论数前十的楼盘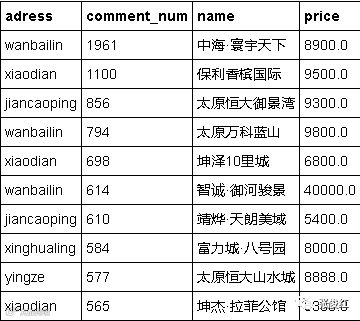
评论数量一定程度上可以说明该楼盘的受欢迎程度,上图表为太原市热评前十的楼盘。
price分析
house.sort_index(by="price",ascending=False).head(10)#按价格进行排序,挑选出价格前十的楼盘
(太原市价格排名前十的楼盘)
house.sort_index(by="price",ascending=False)[:196].price.mean()#计算价格均值
house.sort_index(by="price",ascending=False)[:196].price.std()#计算价格的标准差new_price=house.sort_index(by="price",ascending=False)[:196].price
bins=[0,6000,7000,8000,9000,10000,2000000]
cats=pd.cut(new_price,bins)
price_cut=pd.value_counts(cats)
price_cut.plot(kind="bar",color="grey")
plt.xlabel('price')
plt.ylabel('num')通过计算结果可得:
太原市楼盘的均价为:10592元/平方米。
太原市楼盘的标准差为:9876元。
太原市的楼盘中价格大于10000的楼盘数量最多,其次是(8000-9000),楼盘数量最少对应的价格是(9000-10000)。
太原市楼盘中价格最高的为恒大滨河左岸,一平米价格为12.5万,真实大开眼界,太原还有这么贵的楼盘哈。


推荐阅读
数据分析证明最靠谱的电影评分网站不是 IMDB, 也不是烂番茄,而是...
大数据舆情情感分析,如何提取情感并使用什么样的工具?(贴情感标签)
【干货】找不到适合自己的编程书?我自己动手写了一个热门编程书搜索网站(附PDF书单)

