
以随机森林为例解释特征重要性
了解在Python中确定功能重要性的最受欢迎方法

在许多商业背景下,不仅要建立一个准确的模型而且模型可解释同样重要。通常,除了想知道我们模型的房价预测是什么之外,我们还想知道哪些功能对确定预测最重要。另外,预测客户流失(拥有一个模型可以成功预测哪些客户容易流失)是一个好模型,但是确定哪些变量很重要可以帮助我们及早发现,甚至可以改善产品/服务!
学习‘机器学习模型特征功能的重要性’可以在很多方面使您受益。
例如:
理解模型的逻辑:通过更好地了解模型的逻辑,您不仅可以验证模型的正确性,还可以通过仅关注重要变量来改进模型
更理性的特征选择:可以用于变量选择-您可以删除无关紧要的变量,并且可以在更短的训练时间内获更好的模型。
提高可解释性:为了可解释性而牺牲一些准确性是有意义的。例如,当银行拒绝贷款申请时,它还必须在决策背后有一个推理,该推理也可以呈现给客户
这就是为什么在本文中,我想通过随机森林模型的示例探索不同的方法来解释特征的重要性。同时也适用于不同的模型,从线性回归到XGBoost之类的黑匣子结束。
要注意的一件事是,我们的模型越准确,我们就越相信特征重要性和其他解释。我认为我们建立的模型是相当准确的(因为每个数据科学家都将努力建立这样的模型),在本文中,我将重点放在重要性上。
数据
在此示例中,我将使用波士顿房价数据集(所以是回归问题)。但是本文描述的方法对于分类问题同样适用,唯一的区别是用于评估的度量。
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
boston = load_boston()
y = boston.target
X = pd.DataFrame(boston.data, columns = boston.feature_names)
np.random.seed(seed = 42)
X['random'] = np.random.random(size = len(X))
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size = 0.8, random_state = 42)
准备数据时,非标准方法是在数据集中添加一个随机列。从逻辑上讲,随机列没有因变量的预测能力(自有住房的中位价格为$ 1000),因此它在模型中不应成为重要功能。让我们看看结果如何。
下面,我检查随机特征与目标变量之间的关系。可以看出,散点图上没有图案,相关性几乎为0


这里要注意的一件事是,解释的相关性没有太多意义CHAS,因为它是一个二进制变量,因此应使用不同的方法。
基准模型
我训练了一个普通的随机森林模型以建立基准。我设置了一个randomstate以确保结果可比性。我还使用了boostrap并进行了设置,oobscore = True因此以后可以使用oob_error。
简而言之,关于袋外误差,从原始数据中进行替换采样,随机森林中的每棵树都在不同的数据集上进行训练。这导致每个训练集中约有2/3的不同观察结果。袋外误差是根据所有观察值计算的,但是对于计算每一行的误差,模型仅考虑训练期间未出现行。这类似于在验证集上评估模型。您可以在这里阅读更多内容。
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators = 100,
n_jobs = -1,
oob_score = True,
bootstrap = True,
random_state = 42)
rf.fit(X_train, y_train)
print('R^2 Training Score: {:.2f}
OOB Score: {:.2f}
R^2 Validation Score: {:.2f}'.format(rf.score(X_train, y_train),
rf.oob_score_,
rf.score(X_valid, y_valid)))
R^2 Training Score: 0.93 OOB Score: 0.57 R^2 Validation Score: 0.75
好吧,模型中存在一些过拟合,因为它在OOB样本、验证集上的表现会差多。但是,可以说这已经足够好了,并继续探究特征的重要性(根据训练集的表现来衡量)。一些方法也可以用于验证、OOB集,以对看不见的数据获得进一步的解释。
1.总体功能重要性
总体特征重要性是指在模型级别上得出的特征,即,在给定模型中,这些特征对于解释目标变量最重要。
1.1。默认的Scikit-learn的功能重要性
让我们从决策树开始,以建立一些直觉。在决策树中,每个节点都是在单个要素中分割值的阈值,这样因变量的相似值最终在分割后位于同一集合中。条件基于混乱程度,在分类问题的情况下为基尼系数/信息增益(熵),而对于回归树则为方差。因此,当训练一棵树时,我们可以计算出每个特征对减少加权混乱的贡献。featureimportancesScikit-Learn中的“逻辑”是基于这种逻辑的,如上,在“随机森林”的情况下,我们正在谈论对树木上的混乱减少量进行平均。
优点:
快速计算
易于检索-一个命令
缺点:
有偏见的方法,因为它倾向于夸大连续特征或高基数分类变量的重要性

似乎最重要的3个功能是:
平均房间数
人口地位降低百分比
五个波士顿就业中心的加权距离
令人惊讶的是,一列随机值比以下内容更重要:
每个城镇非零售业务英亩的比例
径向公路通达性指数
超过25,000平方英尺的住宅用地比例
查尔斯河虚拟变量(如果束缚河流,则为1;否则为0)
直观上,此特征对目标变量的重要性为零。让我们看看如何通过不同的方法对其进行评估。
1.2。排列特征重要性
该方法通过观察每个预测变量的随机重排(从而保留变量的分布)对模型的影响来直接衡量特征的重要性。
可以在以下步骤中描述该方法:
训练基线模型,并通过验证集(或在随机森林的情况下为OOB集)记录分数(准确性/R²)。这也可以在训练集上完成,但要牺牲有关泛化的信息。
重新从选定数据集中的一个要素中重新排列值,将数据集再次传递给模型以获得预测并计算此修改后的数据集的影响。特征重要性是基准评分与修改后的(排列的)数据集中的评分之间的差异。
对数据集中的所有要素重复2.。
优点:
适用于任何指标
相当有效
可靠的技术
无需在每次修改数据集时重新训练模型 缺点:
计算上比默认值昂贵 feature_importances
排列重要性高估了相关预测变量的重要性
至于该方法的第二个问题,我已经在上面绘制了相关矩阵。但是,我将使用一个库中的函数来可视化Spearman的相关性。与标准Pearson相关系数的区别在于,该方法首先将变量转换为rank,然后才对rank运行Pearson相关系数。
斯皮尔曼的相关性:
是非参数的
不假设变量之间存在线性关系
寻找单调关系。
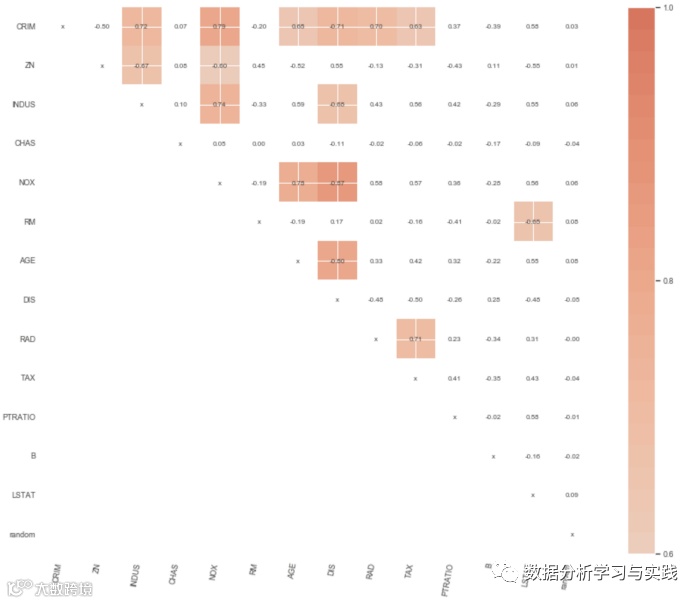
我发现了两个具有此功能的库m让我们仔细研究一下两者,因为它们都有一些独特的功能。
rfpimp
关于该库要注意的一件事是,我们必须提供作为特征模型的指标metric(model, X, y)。这样,我们可以使用更高级的方法,例如使用随机森林的OOB分数。该库已经包含用于该函数的(oobregressionr2_score)。但是为了保持方法的统一,我将在训练集上计算指标。
from sklearn.metrics import r2_score
from rfpimp import permutation_importances
def r2(rf, X_train, y_train):
return r2_score(y_train, rf.predict(X_train))
perm_imp_rfpimp = permutation_importances(rf, X_train, y_train, r2)

该图证实了我们在上面看到的内容,即4个变量比随机变量重要!令人惊讶的是……前4名保持不变。另一个更好的功能rfpimp是它包含处理共线特征问题的功能(这就是显示Spearman的相关矩阵的思想)。
eli5 与的基本方法rfpimp和所采用的方法有一些区别eli5。他们之中有一些是:有参数cv并refit使用交叉验证进行连接。在此示例中,我将它们设置为None,因为我没有使用它,但是在某些情况下可能会派上用场。有一个metric参数,如中的rfpimp接受形式为的函数metric(model, X, y)。如果未指定此参数,则该函数将使用score估计器的默认方法。n_iter -随机洗牌迭代的次数,最终得分是平均值.
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(rf, cv = None, refit = False, n_iter = 50).fit(X_train, y_train)
perm_imp_eli5 = imp_df(X_train.columns, perm.feature_importances_)
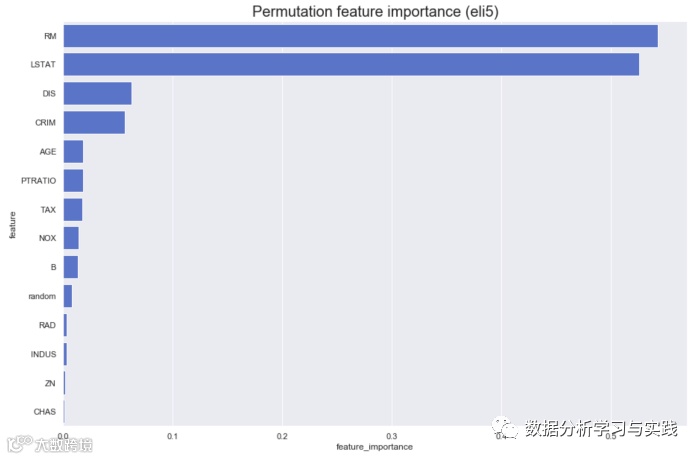
结果与以前的结果非常相似,即使这些结果来自每列多次改组。还有一件好事eli5是,使用置换方法的结果通过Scikit-learn SelectFromModel或进行特征选择确实很容易。
1.3。放置列功能的重要性 这种方法是一种非常直观的方法,因为我们通过比较具有所有特征的模型与具有该特征的模型进行训练来研究特征的重要性。我rfpimp为此下面的方法创建了一个函数(基于的实现),该函数显示了底层逻辑。
优点:
最准确的功能重要性 缺点:
由于针对数据集的每个变体重新训练模型(删除单个要素列之后),因此潜在的高计算成本.
from sklearn.base import clone
def drop_col_feat_imp(model, X_train, y_train, random_state = 42):
# clone the model to have the exact same specification as the one initially trained
model_clone = clone(model)
# set random_state for comparability
model_clone.random_state = random_state
# training and scoring the benchmark model
model_clone.fit(X_train, y_train)
benchmark_score = model_clone.score(X_train, y_train)
# list for storing feature importances
importances = []
# iterating over all columns and storing feature importance (difference between benchmark and new model)
for col in X_train.columns:
model_clone = clone(model)
model_clone.random_state = random_state
model_clone.fit(X_train.drop(col, axis = 1), y_train)
drop_col_score = model_clone.score(X_train.drop(col, axis = 1), y_train)
importances.append(benchmark_score - drop_col_score)
importances_df = imp_df(X_train.columns, importances)
return importances_df

在这里变得很有趣。首先,在这种情况下,负面重要性意味着从模型中删除给定的特征实际上会提高性能。因此在的情况下很高兴看到这一点,但是很奇怪的是,删除后可以看到最高的性能提升DIS,这是以前方法中第三重要的变量。不幸的是,我对此没有很好的解释。如果您有任何想法,请在评论中让我知道!
另外,score除了拟合模型的默认方法外,我们还可以使用袋外误差来评估特征的重要性。为此,我们需要将score上面的要点中的方法替换为model.oobscore(请记住对循环中的基准和模型都这样做)。
2.观察水平特征的重要性
所谓观察级别的特征重要性,是指对解释模型的特定观察结果影响最大的重要性。例如,在信用评分的情况下,我们可以说这些功能对确定客户的信用评分影响最大。
2.1。树解释器
其主要思想treeinterpreter是,它使用随机森林中的基础树来解释每个要素如何对最终价值做出贡献。我们可以观察到预测值(定义为每个特征贡献的总和+初始节点基于整个训练集给出的平均值)如何沿着决策树内的预测路径(每次拆分之后)一起变化以及造成分裂的特征的信息(预测的变化也是如此)。预测函数的公式(f(x))可以写成:

其中c_full是整个数据集(初始节点)的平均值,K是要素总数。这听起来可能很复杂,但是请看一下库作者的示例:

由于随机森林的预测是树木的平均值,因此平均预测的公式如下:
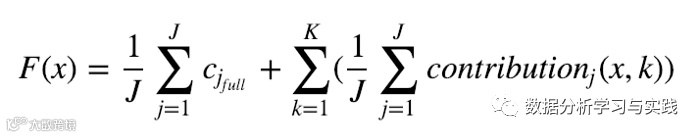
其中,J是森林中的树木数量。我首先确定具有最低和最高绝对预测误差的行,然后尝试查看是什么导致了差异。
使用treeintrerpreter我获得3个对象:预测,偏差(数据集的平均值)和贡献
from treeinterpreter import treeinterpreter as ti, utils
selected_rows = [31, 85]
selected_df = X_train.iloc[selected_rows,:].values
prediction, bias, contributions = ti.predict(rf, selected_df)
for i in range(len(selected_rows)):
print("Row", selected_rows[i])
print("Prediction:", prediction[i][0], 'Actual Value:', y_train[selected_rows[i]])
print("Bias (trainset mean)", bias[i])
print("Feature contributions:")
for c, feature in sorted(zip(contributions[i],
X_train.columns),
key=lambda x: -abs(x[0])):
print(feature, round(c, 2))
print("-"*20)
对于误差最小的观察,主要贡献者是LSTAT和RM(在以前的情况下,结果是最重要的变量)。在最高错误的情况下,最大的贡献来自DIS变量,克服了在第一种情况下起最重要作用的两个变量。
Row 31
Prediction: 21.996 Actual Value: 22.0
Bias (trainset mean) 22.544297029702978
Feature contributions:
LSTAT 3.02
RM -3.01
PTRATIO 0.36
AGE -0.29
DIS -0.21
random 0.18
RAD -0.17
NOX -0.16
TAX -0.11
CRIM -0.07
B -0.05
INDUS -0.02
ZN -0.01
CHAS -0.01
--------------------
Row 85
Prediction: 36.816 Actual Value: 50.0
Bias (trainset mean) 22.544297029702978
Feature contributions:
DIS 7.7
LSTAT 3.33
RM -1.88
CRIM 1.87
TAX 1.32
NOX 1.02
B 0.54
CHAS 0.36
PTRATIO -0.25
RAD 0.17
AGE 0.13
INDUS -0.03
random -0.01
ZN 0.0
--------------------
更深入的,我们可能也有兴趣在许多变量的加入了贡献(如XOR的情况进行了说明这里)。我将直接转到示例,可以在链接下找到更多信息。
prediction1, bias1, contributions1 = ti.predict(rf, np.array([selected_df[0]]), joint_contribution=True)
prediction2, bias2, contributions2 = ti.predict(rf, np.array([selected_df[1]]), joint_contribution=True)
aggregated_contributions1 = utils.aggregated_contribution(contributions1)
aggregated_contributions2 = utils.aggregated_contribution(contributions2)
res = []
for k in set(aggregated_contributions1.keys()).union(
set(aggregated_contributions2.keys())):
res.append(([X_train.columns[index] for index in k] ,
aggregated_contributions1.get(k, 0) - aggregated_contributions2.get(k, 0)))
for lst, v in (sorted(res, key=lambda x:-abs(x[1])))[:10]:
print (lst, v)
最佳和最差预测情况之间的大部分差异来自房间数量(RM)功能,以及与五个波士顿就业中心(DIS)的加权距离。
2.2 LIME LIME(不可解释的本地模型解释性解释)是一种以可解释且忠实的方式解释任何分类器/回归器的预测的技术。为此,通过用一种可解释的模型对所选模型进行局部逼近来获得一种解释(例如具有正则化或决策树的线性模型)。这些可解释的模型是对原始观测值(在表格数据的情况下为行)的小扰动(添加噪声)进行训练的,因此它们仅提供了良好的局部近似。需要注意的一些缺点:仅使用线性模型来近似局部行为 为获得正确的解释而需要对数据执行的扰动类型通常是特定于用例的 简单(默认)的干扰通常是不够的。在理想情况下,修改将由数据集中观察到的变化驱动 您可以在下面看到LIME解释的输出。输出分为三个部分:1.预测值 2.特征重要性-在回归的情况下,它显示对预测有负面还是正面影响,按绝对影响递减排序。3.所说明行的这些功能的实际值。请注意,LIME已离散化了说明中的功能。这是因为discretize_continuous=True在上面的构造函数中进行了设置。离散化的原因是它为连续功能提供了更直观的解释。
import lime
import lime.lime_tabular
explainer = lime.lime_tabular.LimeTabularExplainer(X_train.values,
mode = 'regression',
feature_names = X_train.columns,
categorical_features = [3],
categorical_names = ['CHAS'],
discretize_continuous = True)
np.random.seed(42)
exp = explainer.explain_instance(X_train.values[31], rf.predict, num_features = 5)
exp.show_in_notebook(show_all=False) #only the features used in the explanation are displayed
exp = explainer.explain_instance(X_train.values[85], rf.predict, num_features = 5)
exp.show_in_notebook(show_all=False)

LIME解释同意,对于这两个观察,最重要的特征是RM和LSTAT,这也由先前的方法表明。 更新:我收到一个有趣的问题:我们应该信任哪种观察级别的方法,因为结果可能会有所不同?这是一个没有明确答案的难题,因为这两种方法在概念上是不同的,因此很难直接进行比较。我想请您参考这个答案,其中解决了一个类似的问题并得到了很好的解释。
结论
在本文中,我展示了几种从机器学习模型(不限于随机森林)中推导特征重要性的方法。我认为,了解结果通常与取得良好结果同样重要,因此,每个数据科学家都应尽力了解哪些变量对模型最重要,以及为什么。这不仅可以帮助您更好地理解业务,还可以进一步改进模型。