
在编写软件的过程中,选择了数据的组织方式就是完成了任务的一半。那么就会有一个问题:解决一个问题的方法有很多。当涉及到组织数据时候,有很多工具可以用于这项工作。关键是哪种工具才是正确的?
无论我们用哪种语言开始编程,我们首先遇到的是数据结构。这是我们可以组织数据的不同方式;variables, arrays, hashes, 和数据结构中的其他对象。但这些还只是数据结构的冰山一角;还有很多,其中一些听起来超级复杂。
对我们来说,这些复杂的东西之一就是linked lists。我知道链接列表已经有好几年了,但我从来没有把它们真正的记在脑子里。我只有在准备算法面试时,有人问我关于链表的问题时,才真正想到它们。我会做一些前期准备,并暂时明白它们是什么,但几个星期后,我又会忘记它们。整个事情是相当低效的,这一切都源于这样一个事实:我知道它们的存在,但我并没有从根本上理解它们! 所以,现在是时候改变这种状况,回答这个问题:到底什么是链表?
线性数据结构
如果我们真的想了解链表的基础知识,核心的是我们要谈谈它们是什么类型的数据结构。
链接列表的一个特点它属于线性数据结构,这意味着它们的构建和遍历遵循一个顺序。我们可以把线性数据结构想象成:为了到达列表的末尾,我们必须按顺序穿过列表中的所有组件(items)。然而,非线性结构与线性结构恰恰相反。在非线性数据结构中 ,组件(item)不必按顺序排列,这意味着我们访问时可以不按顺序遍历数据结构。

我们可能并不总是意识到线性结构与非线性结构的区别,但我们每天都在与线性和非线性数据结构打交道! 当我们把数据组织成哈希(有时称为 字典)时,我们正在实现一种非线性数据结构。树和图也是非线性数据结构,我们以不同的方式进行遍历,但我们在今年晚些时候会更深入地讨论它们。
同样,当我们在代码中使用 arrays 时,我们是在实现一种线性数据结构! 把数组(arrays)和链表(linked list)看作是我们对数据进行排序的类似方式有助于我们理解。在这两种结构中,他们都必须按顺序进行。但是,是什么让数组和链接列表有所不同呢?
内存管理
数组和链表之间最大的区别是它们在计算机中使用内存的方式。我们这些使用Ruby、JavaScript或Python等动态类型语言的人,在日常编写代码时不必考虑数组使用多少内存,因为这个过程经过几层抽象,最终导致我们根本没有考虑过内存分配问题。
但这并不意味着内存分配没有发生! 抽象并不神奇,它只是把那些你不需要一直看到或处理的东西藏起来而已。即使我们在写代码时不需要考虑内存分配,如果我们想真正理解链表中发生了什么,是什么让它变得如此通用,我们就必须深入到最基本的层面。
我们已经了解了二进制以及数据如何被分解成比特和字节。就像字符、数字、单词、句子需要字节的内存来表示一样,数据结构也是如此。
数组:
当一个数组被创建时,它需要一定量的内存。如果我们有7个字母需要存储在一个数组中,我们就需要7个字节的内存来表示这个数组。但是,我们需要所有的内存在一个连续的块中。也就是说,我们的计算机需要找到7个字节的内存,这些内存是空闲的,一个字节挨着一个字节,都在一个地方。
链表:
另一方面,当一个链表诞生时,它不需要7个字节的内存都在一个地方。一个字节可以在某个地方,而下一个字节可以完全存储在内存的另一个地方!这就是链接列表。链接列表不需要占用单一的内存块;相反,它所使用的内存可以分散在各个地方。

静态与动态数据结构的内存分配
阵列和链表的根本区别在于,数组是静态数据结构,而链表是动态数据结构。静态数据结构需要在结构创建时分配所有的资源;这意味着即使结构的大小增加或缩小,元素被添加或删除,需要事先给定的大小和内存量。如果需要向静态数据结构添加更多的元素,而它没有足够的内存,你需要复制该数组的数据,然后用更多的内存重新创建它,以便可以向它添加元素。
另一方面,一个动态的数据结构可以在内存中收缩和增长。它不需要分配固定数量的内存,它的大小和形状可以改变,它需要的内存数量也可以改变。
现在,我们已经可以开始看到数组和链表之间的一些主要区别。但这引出了一个问题。为了回答这个问题,我们需要看一下链表的结构方式,是什么让链表的内存分散在各个地方?
链表的组成
一个链表可以很小,也可以很大,但无论大小,构成它的部分其实都很简单。一个链表是由一系列的节点组成的,它们是列表的基本元素。
列表的起点是对第一个节点的引用,它被称为头。几乎所有的链接列表都必须有一个头部,因为这实际上是列表及其所有元素的唯一入口点,没有它,你就不知道从哪里开始! 列表的末端不是一个节点,而是一个指向null的节点,或一个空值。
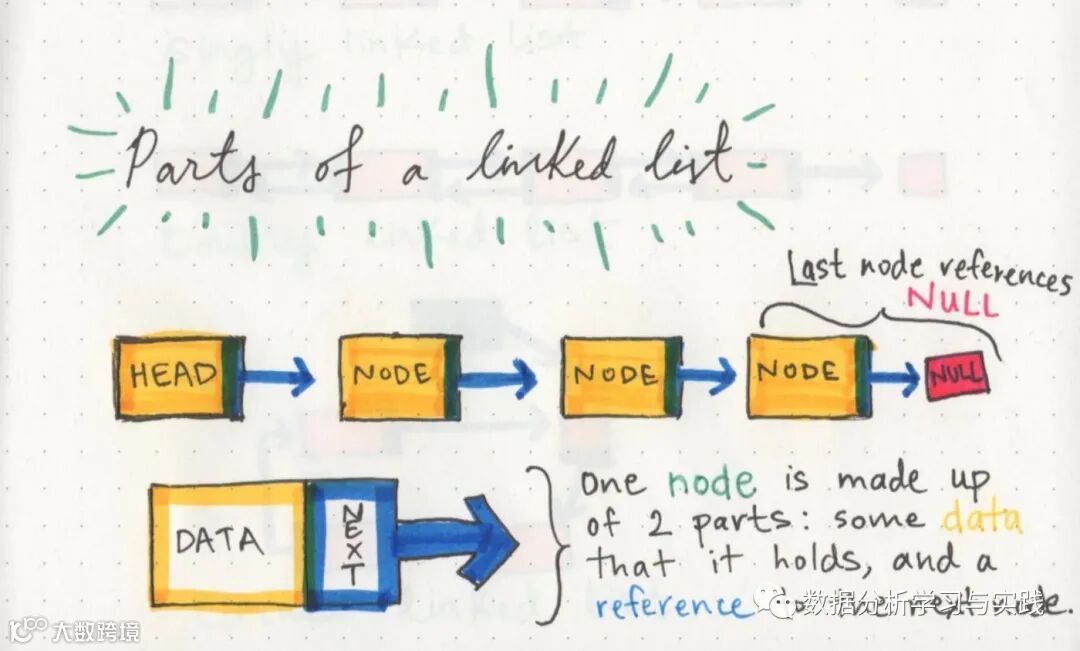
链表的部分:其实都是一堆节点。
单个节点也很简单。它只有两部分。数据,或者说该节点包含的信息,以及对下一个节点的引用。
如果我们能够理解这一点,那么我们就成功了一半。节点的工作方式非常重要,也非常强大,可以概括为这样。
一个节点只知道它包含哪些数据,以及它的邻居是谁。
单个节点不知道链表有多长,甚至不一定知道它在哪里开始,在哪里结束。一个节点所关心的是它所包含的数据,以及它的指针指向哪个节点--列表中的下一个节点。
这就是为什么链接列表不需要连续的内存块的根本原因。因为单个节点有 "地址"信息或对下一个节点的引用,它们不需要像数组中的元素那样紧挨着住。相反,我们可以依靠这样一个事实:我们可以通过对下一个节点的指针引用来遍历我们的列表,这意味着我们的机器不需要为了表示我们的列表而封锁一块内存。
这也是为什么链接列表可以在程序执行过程中动态地增长和缩小的原因。用一个链接列表增加或删除一个节点就像重新排列一些指针一样简单,而不是复制一个数组的元素。然而,链接列表也有一些缺点,我现在还没有向你提及--但下次会有更多内容。
现在,我们就沉浸在链表有多酷的光辉之中吧
各种形状和大小的列表
尽管链表的各个部分没有变化,但我们构造链表的方式可以有很大的不同。像软件中的大多数东西一样,根据我们要解决的问题,一种类型的链表可能是比另一种更好的工作工具。
单轨链表是最简单的链表类型,只基于它们只向一个方向发展的事实。有一个单轨链表,我们可以在列表中遍历;我们从头节点开始,从根部开始遍历,直到最后一个节点,这将结束于一个空的空值。
但是就像一个节点可以引用它后面的邻居节点一样,它也可以有一个指向它前面的节点的引用指针!这就是我们所说的节点。这就是我们所说的doubly linked list,因为每个节点中都有两个引用:对下一个节点的引用,以及对上一个节点的引用。如果我们希望不仅能在单一轨道或方向上遍历我们的数据结构,而且还能向后遍历,这就很有很高的扩展性。
例如,如果我们希望能够在一个节点和前一个节点之间跳转,而不需要回到列表的最开始,那么双链表将是一个比单链表更好的数据结构。然而,一切都需要空间和内存,所以如果我们的节点必须存储两个参考指针,而不是只有一个,这将是另一件需要考虑的事情。

不同类型的链表
一个环形链接列表有点奇怪,因为它没有一个指向空值的节点作为结束。相反,它有一个节点作为列表的尾部(而不是传统的头部节点),而尾部节点之后的节点是列表的开始。这种组织结构使得在列表的末端添加东西变得非常容易,因为你可以从尾部节点开始遍历它,因为第一个元素和最后一个元素是相互指向的。循环链表可以开始变得非常疯狂,因为我们可以把单链表和双链表都变成循环链表!但不管链表有多复杂,我们都可以把它变成循环链表。
但是,不管一个链表有多复杂,如果我们能记住节点的基本原理,记住它是如何工作的,记住我们列表中的不同指针引用是如何结构的,就没有什么链表是我们不能解决的
在本系列的第二部分,我们将深入研究链表的空间时间复杂性,以及它们与它们的数组的比较。我保证,这实际上比听起来要有趣得多!