
在数据探索中,很少有比反复运行同一个单元格,每次都稍微改变输入参数更低效的操作。尽管知道这一点,我仍然发现自己反复执行单元格只是为了做最细微的改变,例如,为一个函数选择不同的值,选择不同的日期范围进行分析,甚至调整一个plotly可视化的主题。这不仅效率低下,而且令人沮丧,打乱了探索性数据分析的流程。
这个问题的理想解决方案是采用交互式控件来改变输入,而不需要重写或重新运行代码。幸运的是,正如Python中经常出现的情况一样,已经有人遇到了这个问题,并开发了一个很好的工具来解决这个问题。在这篇文章中,我们将看到如何开始使用IPython widgets(ipywidgets),你可以用一行代码构建交互式控件。这个库可以让我们把Jupyter Notebooks从静态文档变成交互式仪表盘,非常适合探索和可视化数据。
你可以通过点击下面的图片查看mybinder上的这篇文章中的小部件的完全交互式运行notebook。

IPython小部件,不幸的是,不能在GitHub或nbviewer上渲染,但你仍然可以访问笔记本并在本地运行。


1. 开始使用IPywidgets
第一步,像往常一样,安装库:
pip install ipywidgets
安装完成后,你就可以用以下方法激活Jupyter Notebook的小部件
jupyter nbextension enable --py widgetsnbextension
要与JupyterLab一起使用,请运行。
jupyter labextension install @jupyter-widgets/jupyterlab-manager
要在笔记本中导入ipywidgetslibrary,请运行
import ipywidgets as widgets
from ipywidgets import interact, interact_manual
2. 单行交互式控件
假设我们有以下带有文章统计信息的数据框:
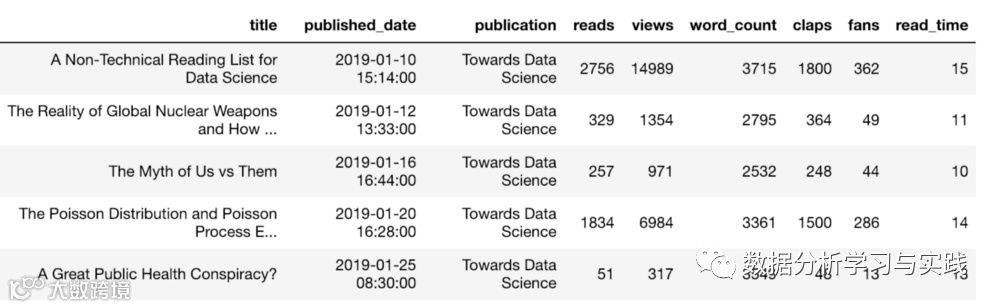
df.loc[df['reads']> 1000]
但是,如果要显示拍手超过500个的文章,则必须编写另一行代码:
df.loc[df['claps']> 500]
如果我们不编写更多代码就可以快速更改这些参数(列和阈值),那不是很好吗?试试这个:
@interact
def show_articles_more_than(column ='claps',x = 5000):
return df.loc [df [column]> x]

# Interact with specification of arguments
@interact
def show_articles_more_than(column=['claps', 'views', 'fans', 'reads'],
x=(10, 100000, 10)):
return df.loc[df[column] > x]
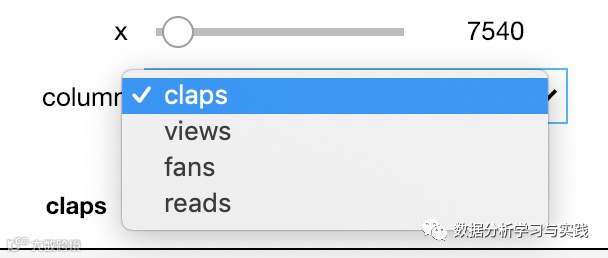
现在,我们得到了一个列的下拉菜单(列表中的选项)和一个限制在一个范围内的整数滑块(格式是(开始,停止,步骤))。请阅读文档,了解函数参数如何映射到widget的全部细节。我们可以使用同样的@interact装饰器来快速地将任何普通函数变成一个交互式widget。例如,我们可能会在一个目录下有很多图片,我们想快速浏览。
import os
from IPython.display import Image
@interact
def show_images(file=os.listdir('images/')):
display(Image(fdir+file))

现在我们可以快速循环浏览所有图像,而无需重新运行单元。如果你正在构建一个卷积神经网络,并且想要检查你的网络错过分类的图像,这实际上可能是有用的。小组件在数据探索中的用途是无限的。另一个简单的例子是寻找两列之间的相关性。
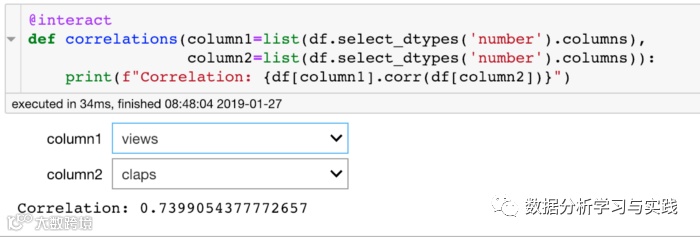
3. plot的小工具
交互式小组件对于选择要绘制的数据特别有帮助。我们可以使用同样的@交互式装饰器来实现数据的可视化。
import cufflinks as cf
@interact
def scatter_plot(x=list(df.select_dtypes('number').columns),
y=list(df.select_dtypes('number').columns)[1:],
theme=list(cf.themes.THEMES.keys()),
colorscale=list(cf.colors._scales_names.keys())):
df.iplot(kind='scatter', x=x, y=y, mode='markers',
xTitle=x.title(), yTitle=y.title(),
text='title',
title=f'{y.title()} vs {x.title()}',
theme=theme, colorscale=colorscale)


现在,只有当按钮被按下时,情节才会被更新。这对于需要一段时间才能返回输出的函数很有用。
3. 扩展交互式控件的功能
为了从IPywidgets库中获得更多,我们可以自己制作widgets,并在interest函数中使用它们。我最喜欢的widget之一是DatePicker。假设我们有一个函数statsforarticlepublishedbetween,它接收一个开始和结束日期,并打印所有在这两个日期之间发表的文章的统计数据。我们可以使用下面的代码来实现这个交互式的功能.
# Create interactive version of function with DatePickers
interact(stats_for_article_published_between,
start_date=widgets.DatePicker(value=pd.to_datetime('2018-01-01')),
end_date=widgets.DatePicker(value=pd.to_datetime('2019-01-01')))
现在,我们得到了两个交互式的日期选择部件,并将其值传递到函数中(详见笔记本)。

同样,我们也可以使用相同的 DataPicker 交互式部件制作一个函数,绘制一列的累计总数,直到某个日期。

如果我们想让一个widget的选项依赖于另一个widget的值,我们使用观察函数。在这里,我们改变图像浏览器函数,以选择目录和图像。显示的图像列表会根据我们选择的目录进行更新。
# Create widgets
directory = widgets.Dropdown(options=['images', 'nature', 'assorted'])
images = widgets.Dropdown(options=os.listdir(directory.value))
# Updates the image options based on directory value
def update_images(*args):
images.options = os.listdir(directory.value)
# Tie the image options to directory value
directory.observe(update_images, 'value')
# Show the images
def show_images(fdir, file):
display(Image(f'{fdir}/{file}'))
_ = interact(show_images, fdir=directory, file=images)


4. 可重复使用的小部件
当我们想在不同的单元格中重用widgets时,我们只需要将它们分配到interact函数的输出中。
def show_stats_by_tag(tag):
return(df.groupby(f'<tag>{tag}').describe()[['views', 'reads']])
stats = interact(show_stats_by_tag,
tag=widgets.Dropdown(options=['Towards Data Science', 'Education',
'Machine Learning', 'Python', 'Data Science']))
现在,要重用stats widget,我们可以在单元格中调用stats.widget。

这让我们可以在笔记本上重复使用我们的小组件。请注意,这些小组件是相互绑定的,这意味着一个单元格中的值会自动更新到你在另一个单元格中为同一小组件选择的值。
我们还没有涵盖IPywidgets的所有功能。例如,我们可以将数值连接在一起,创建自定义部件,制作按钮,建立动画,创建带标签的仪表盘等等。更多的用法请看文档。即使这里涉及的内容不多,我也希望你能看到交互式控件是如何增强笔记本工作流程的!

二、结论 Jupyter Notebook是一个很好的数据探索和分析环境。然而,就其本身而言,它并没有提供最好的功能。使用像笔记本扩展和交互式小部件这样的工具,可以让笔记本活起来,让我们作为数据科学家的工作更加高效。此外,在笔记本中构建widget并使用它们简直太有趣了! 编写大量的代码来重复完成同样的任务并不令人愉快,但使用交互式控件可以为我们的数据探索和分析创造一个更自然的流程。