
把哈希表从书架上拿下来
实话实说:如果让你每周学习理论上的东西,就会让人感到单调。尽管学习理论方法很重要,但同样关键的是要理解我们为什么要踏上疯狂的道路来开始学习它。换句话说--我们在这里一起学习的理论的点是什么?
有时,这可能是一个有点棘手的问题。如果你还不知道大O符号,就很难理解广度优先搜索。而大O符号对你来说没有任何意义,除非你在算法的背景下看到了它的作用。
但是,每隔一段时间,我们就会很幸运地遇到最完美的比喻。比喻是一种通过类比学习的好方法,它们对于说明其他复杂的概念很有用。我花了几天时间试图理解我最近才认识的一个数据结构,只有在这个隐喻的背景下,我才真正开始掌握它。
所以,让我们来看看我们是否能一起解读。
书架上的书
如果你像我一样搬到了全国各地,你可能对拆开所有包裹的恐惧记忆犹新。或者,也许你已经屏蔽了这一切,在这种情况下:做得很好 上周我在拆开我所有的书时,发现自己把它们胡乱地放在书架上,没有任何顺序,也没有任何逻辑。

我们可以把我们的藏书看作是一个数据集。
我拥有很多书,当然,但我没有那么多书,以至于我很难找到一本。这让我想到了图书馆和它们巨大的藏书,以及它们实际上是如何组织的。
想象一下,如果世界上所有的图书馆都不对其书籍进行整理或分类?或者,想象一下,如果它们是按超级复杂的东西分类的......比如按ISBN号码?
我们都会过得更好,因为图书馆是如此有条不紊地组织。但是他们是怎么想出来的呢?事实上,任何人都会想出一个好办法,在大量的东西中进行分类并找到一个项目?
希望你的脑子里刚刚亮起一盏明灯,你和我的想法一样。这是个计算机科学问题!_
如果我们把这个问题抽象为程序化的术语,我们可以把我们的藏书视为我们的数据集。你可以想象,如果我们根本没有组织我们的书,那么我们很有可能在找到我们要找的书之前,必须要搜索书架上的每一本书。如果我们按国际标准书号或出版年份来组织我们的书,我们仍然要翻阅其中的一个子集,因为从书架上的所有物品中找到一件物品仍然有点困难。
在这一点上,我们已经熟悉了许多不同的数据结构--也许我们可以用其中一个来处理我们的数据集?让我们来试试它们的大小。

将一个库想象成一个数据结构
使用一个数组或[[链表]]怎么样?
好吧,这可能在容纳我们所有的数据方面工作得不错。然而,这真的能解决我们在数据集中搜索的问题吗?让我们想一想。为了使用链表或数组找到一本书,我们仍然必须搜索每一个节点,在最坏的情况下,我们要找的数据是在最后一个节点。这基本上意味着,我们搜索所有书籍所需的时间与我们有多少本书直接相关,这就是 线性时间 或O(n)。
如果我们对我们的链接列表进行排序,而不是随机添加数据呢?好吧,这将会更有帮助,因为我们可以在我们的链表上实现 二进制搜索 。请记住,我们可以将二进制搜索应用于[[二叉树搜索]],这就是我们在这种情况下所拥有的。我们可以将我们的大型分类链表或数组分割成较小的子数组,并缩小范围以寻找我们要找的书。然而,即使在最好的情况下,二进制搜索也只能让我们达到对数时间,或O(log n)。当然,这比线性时间要好,但是......这些看起来都不是搜索一本书的最有效方法。
如果有一种方法可以即时查找一本书,而不需要搜索所有的东西,那就太棒了。当然,一定有更好的方法来做这件事。
#映射使我们的生活更容易
好了,好了,我们今天只是学习了一个很酷的数据结构--而不是发明一个新的数据结构!我想我终于应该让你知道了。我想我终于应该让你知道这个秘密了:有一个更好的方法来搜索我们的数据集。正如你可能已经猜到的,它叫做**哈希表。
哈希表是由两个不同的部分组成的。一个数组,你已经很熟悉了,而一个哈希函数,这可能是一个新的概念!那么为什么是这两个部分呢?那么,为什么是这两部分呢?好吧,数组是实际存放数据的地方,而哈希函数或多或少是我们决定数据存放位置的方式--以及当时间到了,我们如何把它从数组中取出来!这就是哈希表。

究竟什么是哈希表?
在上面的例子中,我们把我们的书架重组为一个哈希图 我们的书架一开始是空的,为了把书(我们的数据)添加到书架上,我们把书传给一个哈希函数,它告诉我们应该把它放在哪个书架上。
哈希表有很多有趣的原因,但对于我们的目的来说,使它们如此有效的原因是它们创建了一个**映射,也就是两组数据之间的关系。哈希表是由一组数据对组成的:一个键和一个值,通常被称为(k, v)。这里的想法是,如果你在一组数据中拥有键,你可以在另一组数据中找到与之对应的值。
在哈希表的情况下,是哈希函数创建了这个映射。因为我们是在用数组工作,所以键是数组的索引,而值是住在该索引的数据。散列函数的工作是将一个项目作为输入,计算并返回该项目在散列表中的键值。
好了:如果我们真的要沉下心来研究这个话题,我们需要一个例子。让我们把前面的书架抽象出来,进一步简化它。在下面的例子中,我们看到的是一个书名的哈希表。哈希表有两个可预测的部分:一个数组,和一个哈希函数。

一个大小为12的哈希表
我们的哈希表的大小为12,这最终意味着每本书都需要存储在这12个槽中的某个地方,这些槽也被称为**哈希桶。
等一下:那个哈希函数是如何决定把这些书放在哪里的!?如果你仔细看一下,你会发现我们使用了模运算符 %,你可能已经见过了。当一个数字除以另一个数字时,模运算符返回余数(如果数字可以被平均分割,则返回0)。那么,我们的散列算法在做什么?也许你已经知道了这里的模式
我们的散列函数将标题中的字符数加起来,然后将加起来的总数除以表格的大小。例如,"The Great Gatsby "有14个字符(忽略空格),除以12,即表格的大小,我们得到的余数是 2。因此,我们的哈希函数将确定 "The Great Gatsby"应该在哈希桶中,索引为 2。
我们可以在代码中写出我们的哈希函数的实际情况。
好吧,这很简单! 事实上,这几乎是......_太简单了。我觉得现在要出问题了。让我们继续下去,看看我们的哈希函数能走多远。我们将尝试另一个书名:"The Old Man and the Sea"。
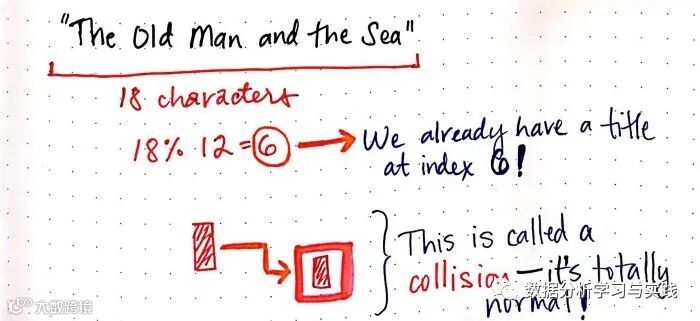
当两个元素应该被插入到数组的同一位置时,就会发生碰撞。
哦,不,我有预感这将会发生
当我们把 "The Old Man and the Sea "输入我们的哈希函数时,它返回 "6"。这很糟糕,因为我们在哈希桶 6处已经有了一个 TheSoundandtheFury! 这是很糟糕的,对吗?
嗯,事实证明,这一点都不坏。这实际上是很正常的。事实上,它是如此正常,以至于这种现象甚至有一个名字:碰撞,当两个元素被插入到数组中完全相同的地方--换句话说,在同一个哈希桶中,就会发生这种现象。
这对我们的哈希函数有什么启示?
首先,我们可以肯定的是,没有一个哈希函数会永远为每个给它的项目返回一个唯一的哈希桶值。事实上,一个哈希函数总是会向同一个输出(哈希桶)输入多个元素,因为我们的数据集的大小通常会大于我们哈希表的大小。
但为什么会出现这种情况呢?
超酷的恒定时间
如果我们在实际情况下更多地考虑哈希表,就会很清楚,我们几乎_总是在每个哈希桶中有多个元素。
一个应用于现实世界问题的哈希表的好例子是电话簿。一个电话簿是巨大的,它包含了住在某个地区的每个人的所有数据和联系信息。
它是如何组织的呢?当然是按姓氏。字母表的每个字母都会有很多人有这个姓氏,这意味着我们在每个字母的哈希桶里都会有很多数据。

依靠字母化的哈希函数总是会产生26个哈希桶。
电话簿或字典的哈希函数总是将任何输入的数据归入26个桶中的一个--每个字母一个桶。这最终是相当有趣的,因为这实际上意味着我们永远不会有一个哈希桶(或者在这种情况下,一个字母)是空的。事实上,我们会有接近于每个字母开头的姓氏的均匀分布。
事实上,这也是好的散列算法的一个重要组成部分。在所有可能的哈希桶中,数据的分布是相等的。_但现在先不要想这个问题--我们下周会有更多的讨论。
现在,让我们来看看哈希表的另一个很酷的部分:它们的效率! 无论我们处理的是电话簿、字典还是图书馆,方法都是一样的:我们的哈希函数会告诉我们把数据放在哪里,也会告诉我们从哪里把数据取出来。
 哈希表利用了恒定时间搜索,这也是它的强大之处。
哈希表利用了恒定时间搜索,这也是它的强大之处。
如果不使用哈希表,我们必须搜索整个数据集,可能从数组或链接列表的第一个元素开始。如果我们的项目在列表的最末端--好吧,祝你好运!我们可能在搜索一个长的元素。我们可能要搜索很长时间。事实上,有多少个元素就有多少时间 这就是使用链表、堆栈、队列和数组的主要问题:通过它们搜索某些东西的时间总是线性的,或O(n)。
与哈希表相比,现在我们了解了哈希函数的工作原理后,在两者之间做出选择似乎很容易 如果我们要找一个元素,我们只需要把这个元素传给哈希函数,它就会准确地告诉我们要在数组中的哪个索引--也就是哪个_哈希桶--中寻找。这意味着,即使我们要找的项目在哈希表数组的最末端,我们找到它的时间也与找到数组中第一个元素的时间完全相同
不需要遍历一个庞大的列表,也不需要翻阅图书馆的所有书架:我们可以在恒定的时间内,或者说在O(1)的时间内,快速而轻松地查找我们的数据。在哈希表中插入或删除一个项目也只需要恒定的时间,因为我们总是要靠我们的哈希函数来确定在哪里添加或删除什么东西!
具有恒定搜索时间的算法和数据结构是非常强大的。而且,更重要的是,它们就在我们身边。事实上,你甚至可能没有注意到它们。把这一切带回到我们开始的地方:想想图书馆是如何组织东西的 世界各地的图书馆都使用杜威十进制分类系统,这实际上只是一个有10个桶的哈希表(当然,还有一个复杂的哈希函数,我现在还不太明白)。

下周,我们将深入研究哈希函数和它们的碰撞,并发现如何解决这些冲突,这些冲突如此普遍,以至于有专门的算法来处理它们。在那之前,请试着克制住重新整理书架的冲动。
#资源
我很难缩小与你分享资源的范围,因为这些资源实在是太多了。这并不是一个糟糕的问题。如果你想了解更多关于哈希表和它们如何工作的信息,请查看这些链接。