
 摘要:越来越多的证据表明,气候变化的影响已在全球范围内被观察到。全球环境评估面临评估不断增长的文献的挑战。在这里,我们使用语言模型BERT来识别和分类关于观察到的气候影响的研究,生成一个全面的机器学习辅助证据图。我们估计有102,160(64,958-164,274)篇出版物记录了广泛的观察到的影响。通过结合我们的空间分辨数据库与网格单元级别的人类可归因的温度和降水变化,我们推断,可归因的人为影响可能发生在世界陆地面积的80%,那里居住着85%的人口。我们的结果显示出一个显著的“归因差距”,因为潜在可归因影响的有力证据在高收入国家比在低收入国家更为普遍。虽然在区域和部门层面自信地归因气候影响仍存在差距,但这个数据库展示了人为气候变化当前在全球范围内的潜在影响。
摘要:越来越多的证据表明,气候变化的影响已在全球范围内被观察到。全球环境评估面临评估不断增长的文献的挑战。在这里,我们使用语言模型BERT来识别和分类关于观察到的气候影响的研究,生成一个全面的机器学习辅助证据图。我们估计有102,160(64,958-164,274)篇出版物记录了广泛的观察到的影响。通过结合我们的空间分辨数据库与网格单元级别的人类可归因的温度和降水变化,我们推断,可归因的人为影响可能发生在世界陆地面积的80%,那里居住着85%的人口。我们的结果显示出一个显著的“归因差距”,因为潜在可归因影响的有力证据在高收入国家比在低收入国家更为普遍。虽然在区域和部门层面自信地归因气候影响仍存在差距,但这个数据库展示了人为气候变化当前在全球范围内的潜在影响。
Callaghan, M., Schleussner, CF., Nath, S. et al. Machine-learning-based evidence and attribution mapping of 100,000 climate impact studies. Nat. Clim. Chang. 11, 966–972 (2021). https://doi.org/10.1038/s41558-021-01168-6
研究背景
-
研究问题:这篇文章旨在解决全球环境评估中面临的挑战,即如何系统地识别和分类关于气候变化影响的文献。具体来说,研究使用语言模型BERT来识别和分类关于观察到的气候变化影响的研究,生成一个全面的机器学习的证据地图。 -
研究难点:该问题的研究难点包括:气候变化影响的证据基础不断扩大,手动专家评估难以应对指数级增长的文献;不同研究和学科的方法论和鲁棒性标准差异广泛,需要专家判断;区域和部门层面的气候影响归因存在显著差距。 -
相关工作:该问题的研究相关工作包括:IPCC对观察到的气候变化影响的评估;使用自然语言处理(NLP)技术进行健康科学中的证据综合;以及将系统综述和地图方法扩展到大规模文献的研究。
研究方法
这篇论文提出了一种基于机器学习的气候影响证据和归因映射方法,用于解决气候变化影响文献识别和分类的问题。具体来说,
-
文献检索与筛选:首先,使用Web of Science和Scopus两个大型文献数据库进行系统检索,确保搜索字符串返回IPCC第五次评估报告(AR5)工作组II表18.5-18.9中的所有参考文献。检索到的记录经过去重处理,共得到601,667条记录。
-
机器学习分类:使用BERT模型和其变体DistilBERT进行文本分类。训练数据通过协作筛选和编码2,373个摘要生成,使用监督学习对DistilBERT进行微调,以分类与理解气候变化观察到的影响相关的文档,并预测其影响类别和气候变量。分类器的性能通过嵌套交叉验证进行评估,二元包含分类器达到平均F1分数0.71和ROC AUC分数0.92。

实验设计
-
数据收集:从Web of Science和Scopus数据库中检索到601,667条记录,经过去重处理后得到601,667条记录。 -
样本选择:通过协作筛选和编码2,373个摘要,并使用IPCC AR5工作组II表18.5-18.9中的数据进行自动标记。 -
参数配置:使用DistilBERT模型进行分类,采用嵌套交叉验证进行超参数调优和模型选择。最终模型在测试集上的表现进行评估。
结果与分析
-
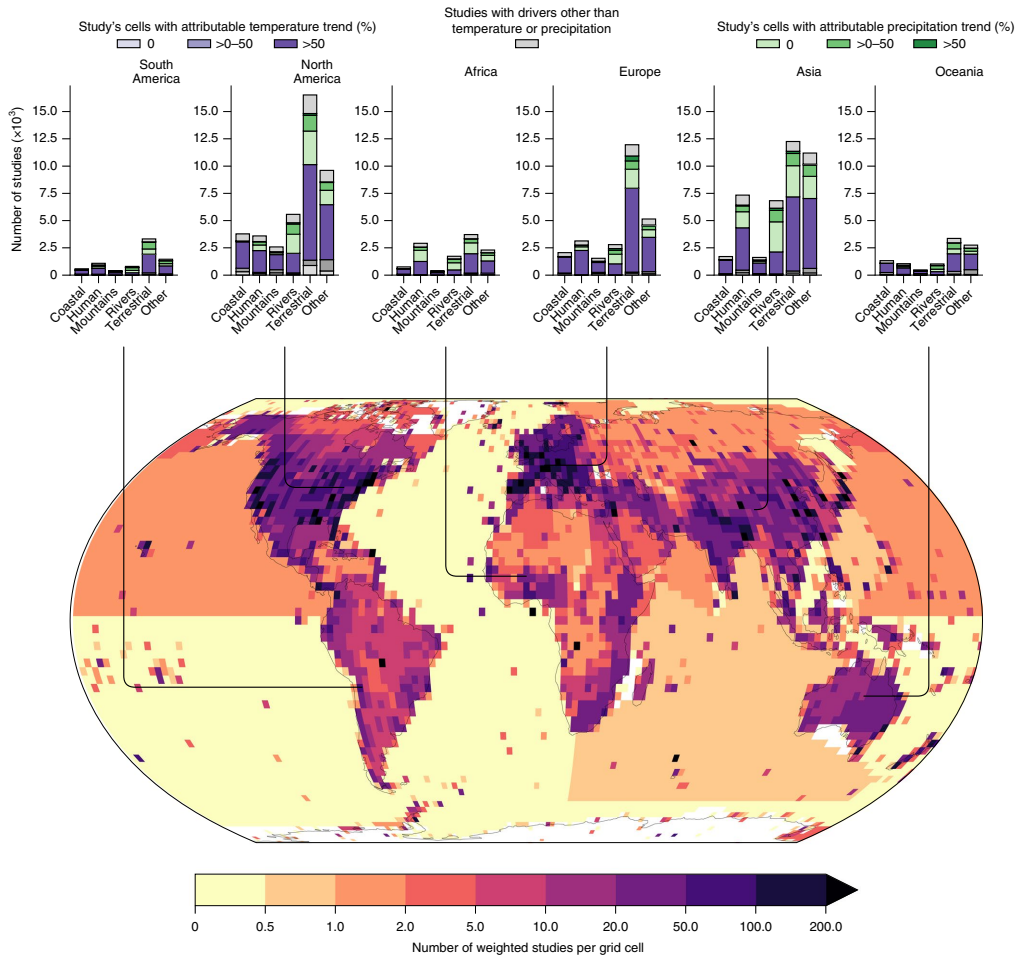
文献分类结果:通过机器学习分类,共识别出102,160篇与气候变化观察到的影响相关的文档。这些文档分布在各大洲,其中北美、亚洲和欧洲的相关研究数量远高于南美洲、非洲和大洋洲。
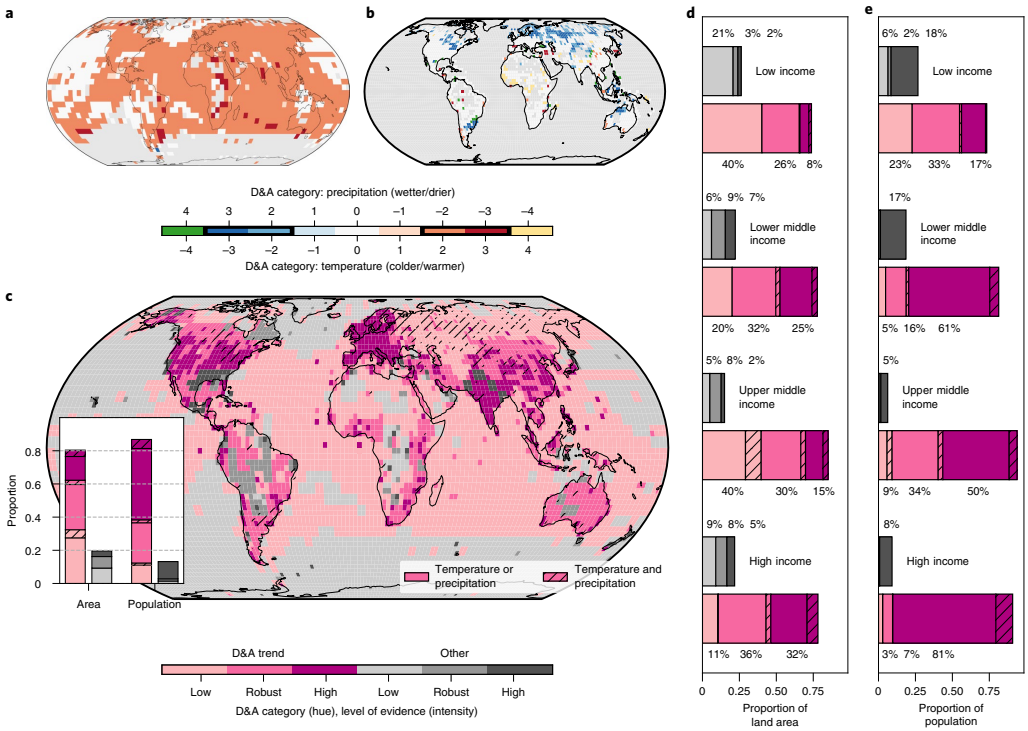
2. 气候影响归因:结合气候模型模拟和观测数据,推断出80%的全球陆地面积(不包括南极洲)的温度和/或降水趋势至少部分可归因于人类活动的影响。这些区域覆盖了85%的世界人口。
3. 证据差距:高收入国家的归因研究密度显著高于低收入国家。低收入国家中有23%的人口生活在低证据区域,而高收入国家仅为3%。
总体结论
这篇论文通过机器学习和GIS分析,生成了一份全面的气候变化影响证据地图。研究表明,尽管大多数世界人口生活在受人类活动影响的气候区域内,但在低收入国家,相关证据仍然不足。该数据库为进一步的区域和本地气候适应行动提供了重要的信息,并揭示了气候变化影响评估中的“归因差距”。未来的研究可以进一步细化分析或扩展归因信号,以提高归因的可靠性。