一段可以实现的Adaboost的代码,作为集成算法理论学习完,以后的练习例子!
1# -*- coding: utf-8 -*-
2"""
3Created on Thu Mar 26 02:40:20 2020
4
5adaboost 算法预测房价 回归分析
6
7@author: Romer
8"""
9
10from sklearn.model_selection import train_test_split
11from sklearn.metrics import mean_squared_error
12from sklearn.datasets import load_boston
13from sklearn.ensemble import AdaBoostRegressor
14from sklearn import tree
15from sklearn.neighbors import KNeighborsRegressor
16# 加载数据
17data=load_boston()
18# 分割数据
19train_x, test_x, train_y, test_y = train_test_split(data.data, data.target, test_size=0.25, random_state=33)
20
21# 使用AdaBoost回归模型
22regressor=AdaBoostRegressor()
23regressor.fit(train_x,train_y)
24pred_y = regressor.predict(test_x)
25mse = mean_squared_error(test_y, pred_y)
26print("房价预测结果 ", pred_y)
27print("均方误差 = ",round(mse,2))
28
29# 使用决策树回归模型
30dec_regressor = tree.DecisionTreeRegressor()
31dec_regressor.fit(train_x,train_y)
32pred_y = dec_regressor.predict(test_x)
33mse = mean_squared_error(test_y, pred_y)
34print("决策树均方误差 = ",round(mse,2))
35
36# 使用KNN回归模型
37knn_regressor=KNeighborsRegressor()
38knn_regressor.fit(train_x,train_y)
39pred_y = knn_regressor.predict(test_x)
40mse = mean_squared_error(test_y, pred_y)
41print("KNN均方误差 = ",round(mse,2))
42
43"""
44如果想要随机生成数据,我们可以使用 sklearn 中
45的 make_hastie_10_2 函数生成二分类数据。
46假设我们生成 12000 个数据,取前 2000 个作为测试集,其余作为训练集
47"""
48
49import numpy as np
50import matplotlib.pyplot as plt
51from sklearn import datasets
52from sklearn.metrics import zero_one_loss
53from sklearn.tree import DecisionTreeClassifier
54from sklearn.ensemble import AdaBoostClassifier
55# 设置AdaBoost迭代次数
56n_estimators=200
57# 使用
58X,y=datasets.make_hastie_10_2(n_samples=12000,random_state=1)
59# 从12000个数据中取前2000行作为测试集,其余作为训练集
60train_x, train_y = X[2000:],y[2000:]
61test_x, test_y = X[:2000],y[:2000]
62# 弱分类器
63dt_stump = DecisionTreeClassifier(max_depth=1,min_samples_leaf=1)
64dt_stump.fit(train_x, train_y)
65dt_stump_err = 1.0-dt_stump.score(test_x, test_y)
66# 决策树分类器
67dt = DecisionTreeClassifier()
68dt.fit(train_x, train_y)
69dt_err = 1.0-dt.score(test_x, test_y)
70# AdaBoost分类器
71ada = AdaBoostClassifier(base_estimator=dt_stump,n_estimators=n_estimators)
72ada.fit(train_x, train_y)
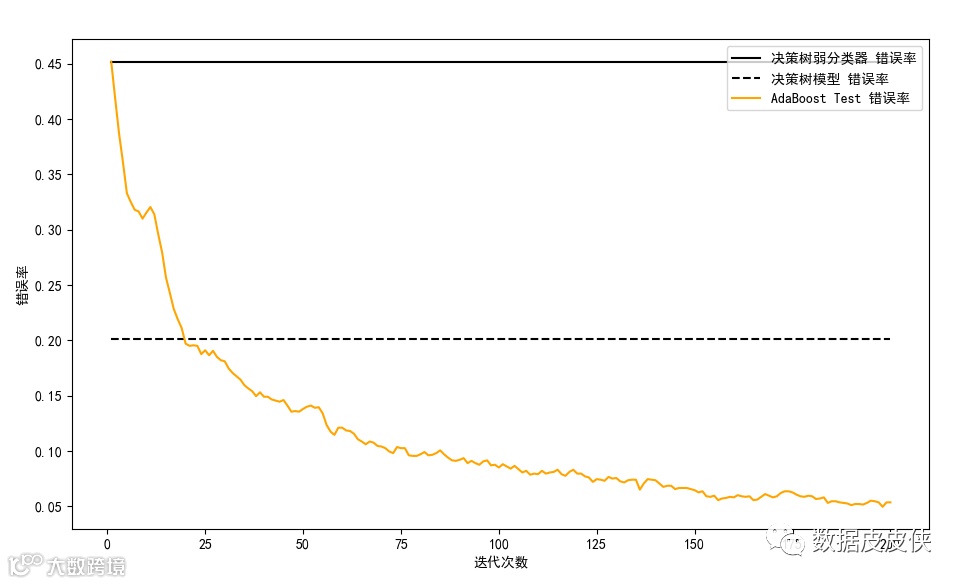
73# 三个分类器的错误率可视化
74fig = plt.figure()
75# 设置plt正确显示中文
76plt.rcParams['font.sans-serif'] = ['SimHei']
77ax = fig.add_subplot(111)
78ax.plot([1,n_estimators],[dt_stump_err]*2, 'k-', label=u'决策树弱分类器 错误率')
79ax.plot([1,n_estimators],[dt_err]*2,'k--', label=u'决策树模型 错误率')
80ada_err = np.zeros((n_estimators,))
81# 遍历每次迭代的结果 i为迭代次数, pred_y为预测结果
82for i,pred_y in enumerate(ada.staged_predict(test_x)):
83 # 统计错误率
84 ada_err[i]=zero_one_loss(pred_y, test_y)
85# 绘制每次迭代的AdaBoost错误率
86ax.plot(np.arange(n_estimators)+1, ada_err, label='AdaBoost Test 错误率', color='orange')
87ax.set_xlabel('迭代次数')
88ax.set_ylabel('错误率')
89leg=ax.legend(loc='upper right',fancybox=True)
90plt.show()
结果显示: